爬取淘宝搜索某商品出现的信息
因为淘宝现在要登录才能进行商品搜索,所以我们先在网页上进行登录,然后获取相关的header与cookie,最后利用参数来登录请求相关页面。
1、登录淘宝
2、随便搜索某一商品,打开网络资源,刷新一下找到search
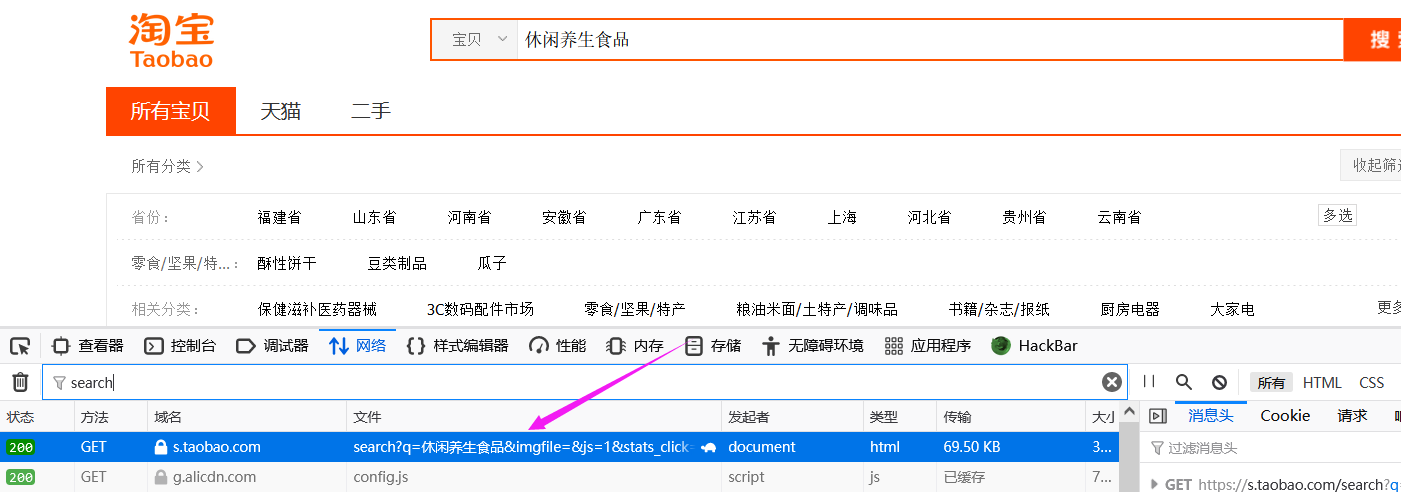
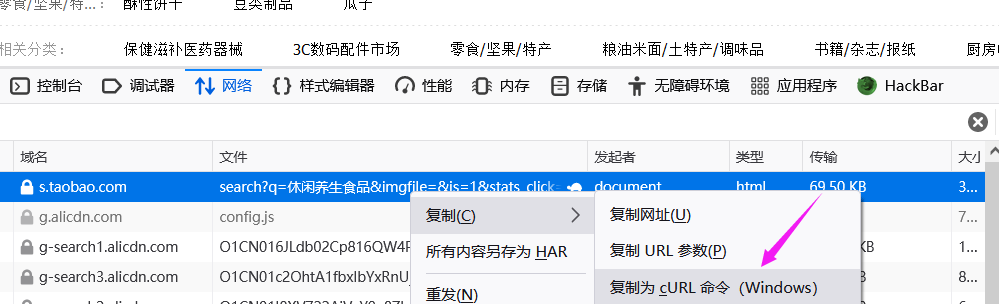
3、右键,复制为cURL
4、在 https://curlconverter.com/ 将上一步复制的curl访问命令转化为python的请求方式。
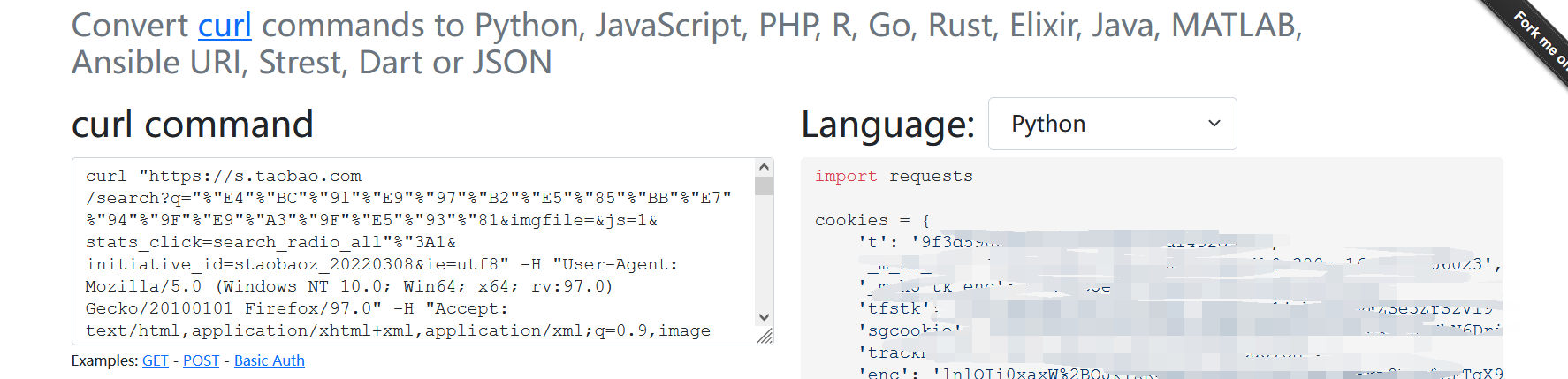
5、复制出上一步转化得到的python请求代码,补充好相关请求和解析数据的代码即可。
完整代码:url中的s参数表示正在访问的页面
1 | #coding=GBK |
爬取知乎中搜索某话题的综合相关内容
如搜索朋克养生,要爬取的页面如下:
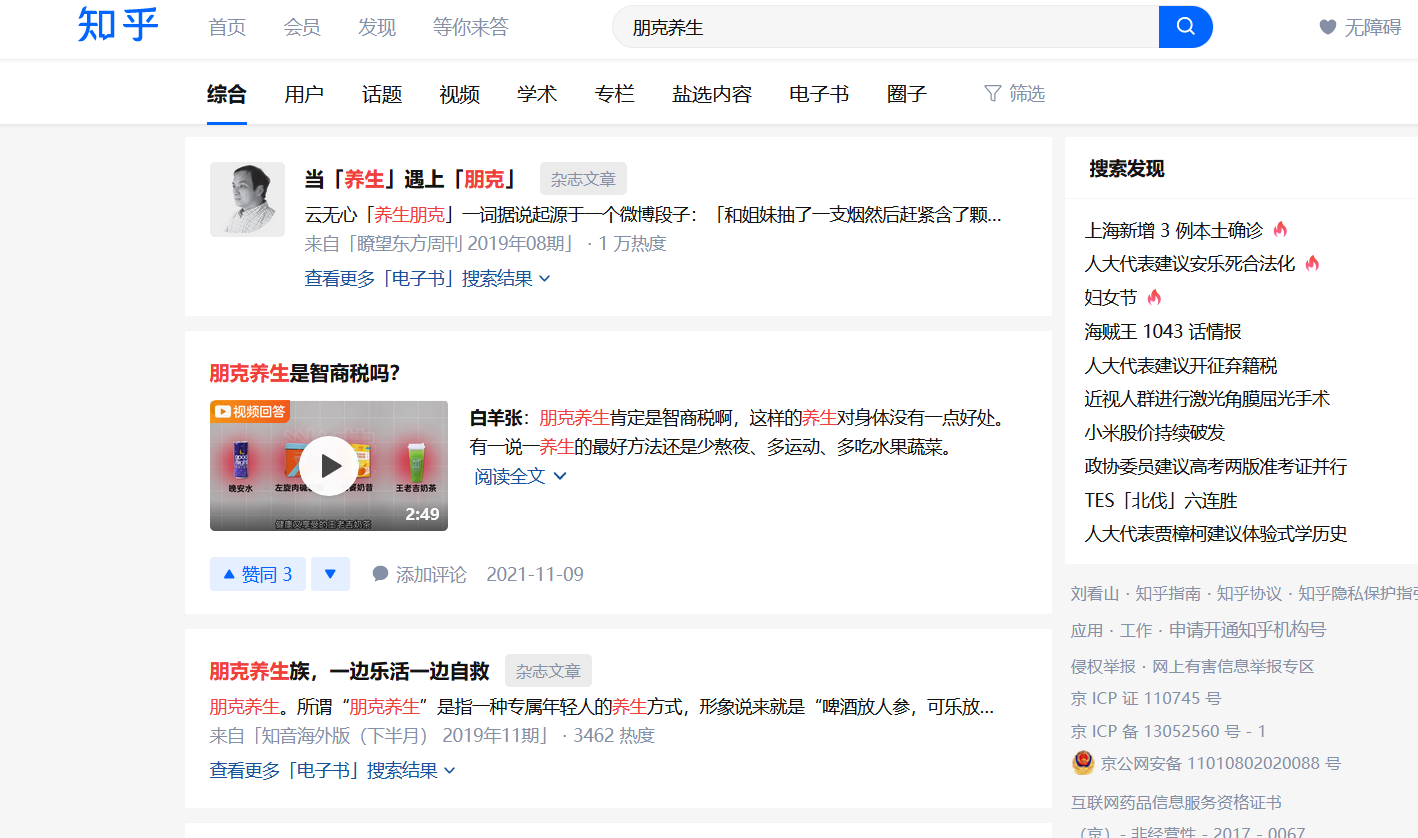
因为是第一次接触爬虫,以为简单的把页面数据请求下来使用正则匹配需要的内容就好了,但发现请求的内容根本没有页面展示出的相关内容,只有一个框架。
经过相关了解后,发现这是一个使用ajax异步加载的页面,也就是说我们需要的数据是在访问页面过程中动态加载的,我们在脚本中请求只能获得静态页面(由于requests模块是一个不完全模拟浏览器行为的模块,只能爬取到网页的HTML文档信息,无法解析和执行CSS、JavaScript代码),接着我从网络资源中的xhr页面中找到真正获取数据的接口:
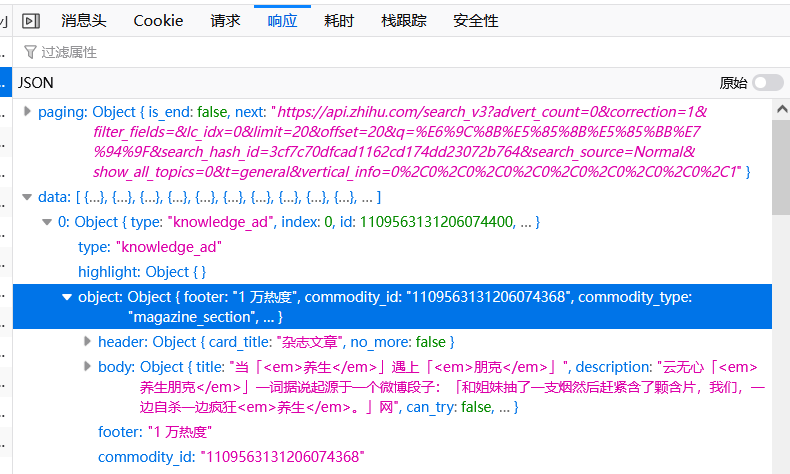
但是直接请求这个接口服务端并不会正确返回,因为有相关字段(x-zse-93,x-zse-96,x-zse-81)进行校验,这也简单,其中x-zse-93与x-zse-81是固定的,我们只需要从js代码中逆向出x-zse-96的计算方法,爬取页面的时候模拟计算一下就好。而弄完,又遇到了其它的问题,访问接口的search_hash_id不止一种,这就使x-zse-96字段的值也不止一种,且相关处理也挺麻烦的,因此我使用了另外一种爬取方法:使用selenium接管本地打开的浏览器然后利用执行js代码对页面滚动条进行滑动,最后获取匹配我们需要的关键信息。(知乎对selenium进行了反爬处理,即对相关字符串进行了检查)
1、本地以一个端口启动chorm
1 | chrome.exe --remote-debugging-port=9222 --user-data-dir="./" |
2、使用selenium接管上一步打开的浏览器,访问要爬取页面的url
3、利用执行js代码的方式不断向下滑动滚动条加载数据,不断加大滚动条与顶部的距离

4、利用相关标签匹配所需要的数据并进行正则匹配
完整代码:
1 | #coding=gbk |