DigitalCircuits
py文件打包的exe,使用pyinstxtractor解包,填充pyc头,最后使用uncompyle6反编译得到py代码。
如题目的名称,此程序中的加法,移位,异或运算都是作者自己从二进制的角度实现的。
加法:

逻辑右移: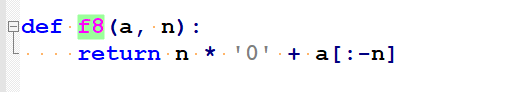
逻辑左移: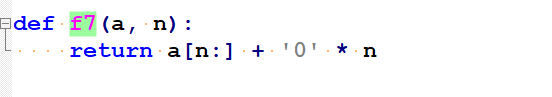
异或:
这样来看此程序就是很明显的tea加密了,只是用二进制运算来实现的。
tea解密:
1 | def tea_decode(enc, k): |
hell_world
字符串定位关键函数,从case7能推出输入长度及case9是加密操作。

其中case9是将输入转化为二进制,只是0和1使用2和3来替换,接着执行的case10是使用硬编码的数组数据与输入进行异或操作且转化为二进制。
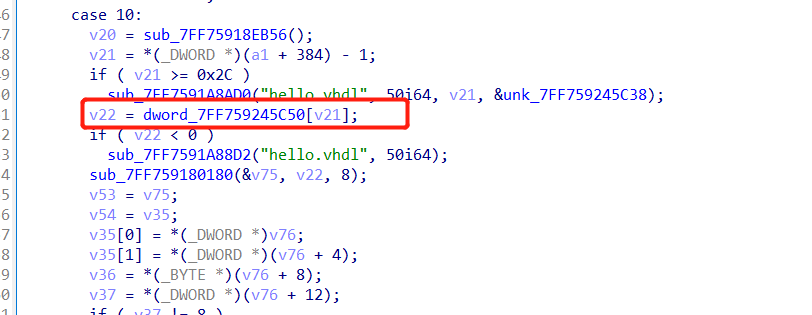
再来看到紧接着case10执行的case11,关键就是比较操作,密文在dword_7FF759245B80数组。
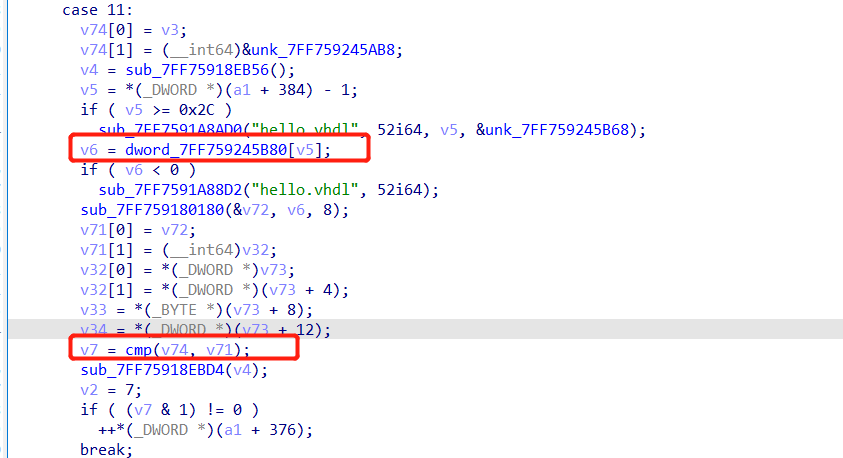
所以说,使用两个数组异或就解密了。
1 | enc |
tttree
程序中的几种花指令:
1、
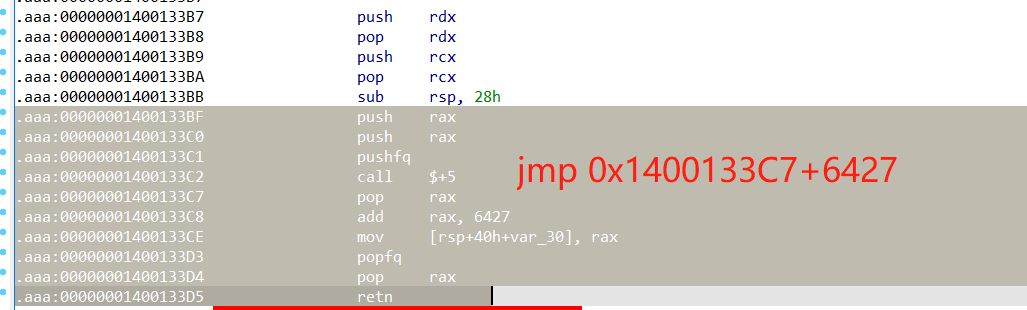
2、
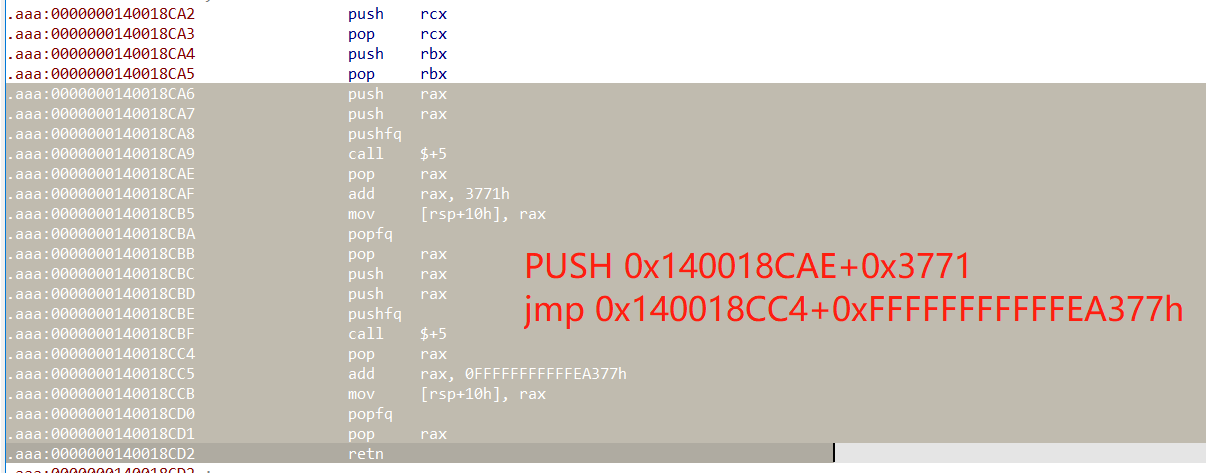
开始想的是把所有汇编代码复制到文本中,用python来提取计算出要跳转的地址,然后记录出要替换的地址及要替换成的汇编代码,最后批量patch一下,但是在做的时候对第二种花指令没有考虑前面的push操作,所以最后弄完没啥效果,就干脆不去除了。
从最后判断入手,有5个error的字符串,因为我将大部分的花指令都正确替换成了对应的jmp,所以从字符串error就能找到对应的被调用地址,调试定位到其中有2个是check输入长度和格式不对时要输出的error。

其次另外3个error是最后的checK加密结果的,不断向上回溯看汇编可以发现最后的check中循环用到了dword_1400073C0这个数组。
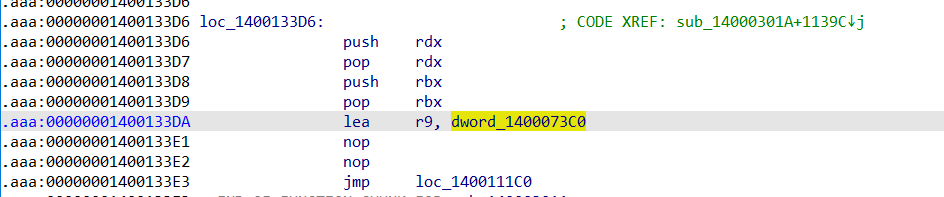
重新打开一个未patch过的程序,在引用了dword_1400073C0数组对应的地址下断点,运行看对应的内存。
另外从其对这个数组的访问下标看到都是乘以了28,因此可以知道这个数据是28个字节为一组,7个4字节变量。
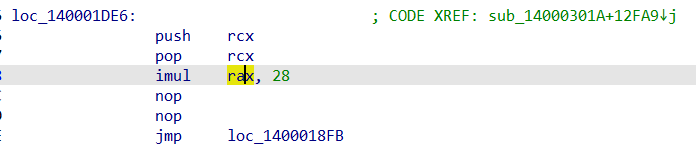
观察这个内存数据,可以发现每组的最后一个4字节变量正好对应我们的输入且在这个数组中的存放顺序就是我们输入顺序,idapython导出数据便于观察。
1 | from ida_bytes import * |
1 | [['A', 0, 19, 5], ['B', 15, 18, 17], ['C', 0, 0, 1], ['D', 0, 11, 2], ['E', 4, 21, 32], ['F', 0, 26, 3], ['G', 0, 0, 1], ['H', 0, 6, 4], ['I', 28, 1, 7], ['J', 0, 3, 2], ['K', 0, 0, 1], ['L', 22, 0, 3], ['M', 0, 0, 1], ['N', 0, 29, 4], ['O', 8, 12, 9], ['P', 10, 0, 3], ['Q', 0, 0, 1], ['R', 14, 13, 7], ['S', 16, 0, 4], ['T', 0, 0, 2], ['U', 25, 24, 29], ['V', 23, 0, 2], ['W', 0, 0, 1], ['X', 0, 0, 1], ['Y', 2, 27, 27], ['Z', 7, 0, 2], ['2', 9, 17, 9], ['3', 0, 0, 1], ['4', 20, 0, 3], ['5', 0, 0, 0], ['6', 0, 0, 0], ['7', 0, 0, 0]] |
再通过看汇编与调试分析出在check时,如果每组的第一个4字节变量与第二个4字节变量不为0,那么他和输入有如下关系:
如果是第一个4字节变量不为0:input[i]+23*i == b[i]
如果是第二个4字节变量不为0:input[i]+23*i == c[i]
另外每次还要check每组的第三个4字节变量是否等于a[i]
以上的a,b,c分别对应程序中如下的三个硬编码密文表: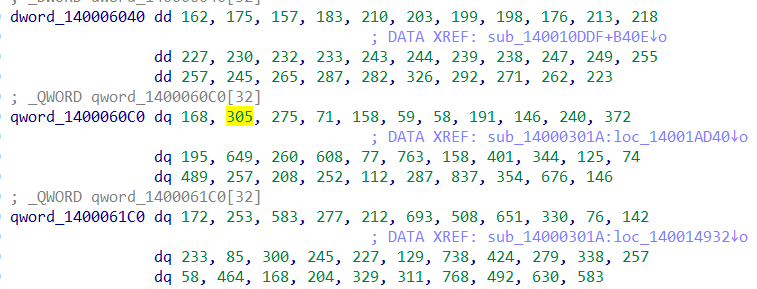
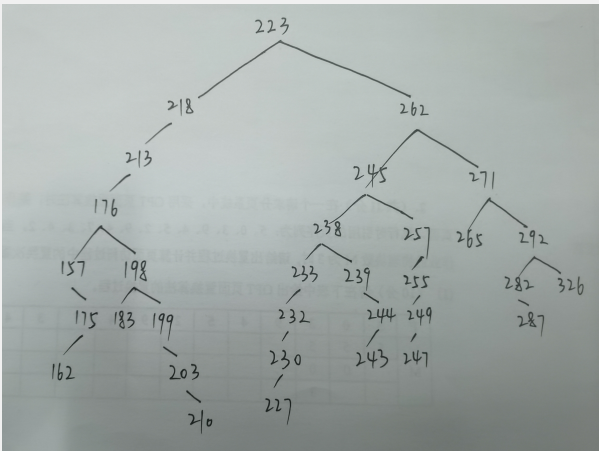
再通过调试dword_1400073C0的填充与最后check过程,能得出这是一个树的构造过程(又根据提示确定是二叉树),那么我们上面看到的每组28个字节的数据应该就是一个节点,且每组的第一个4字节变量与第二个4字节变量分别指向的它的左子树和右子树的位置,下标从1开始,0表示空,这也正好对应dword_1400073C0数组的第一个28字节单元为0。
为了知道这个二叉树的构成,我输入测试数据 ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 ,然后根据dword_1400073C0数组数据画出生成的二叉树,但完全不符合二叉搜索树的构造,,后面好久才反应过来这个二叉树并不是将输入的ascii值作为权重值,而是将输入经过运算后的值,这个值就对应每组28字节数据中的第三个4字节数据,这样也就正好符合我画出的二叉树了。
接着跟踪输入的运算,得出对对输入的运算就是一个加法值,而这个加法的值生成是将 19600416 作为初始化数据,然后一些乘法、模除、加法运算。
写成python代码:
1 | x = [] |
再接着就是根据我画出的二叉数看汇编与调试check过程,得出是后序遍历取数据进行对比的,那么我们就可以根据密文数组a(上面提到的)画出还原的二叉树,因为这个是二叉搜索树,所以根据后序遍历是能唯一确定一棵二叉树的。
还原出二叉数后,接着就是还原出他们的下标了,先从要判断的前三个叶子节点开始用他们之间的满足的关系爆破出开始的正确下标:
1 | a = [0, 0x00000000000000A8, 0x0000000000000131, 0x0000000000000113, 0x0000000000000047, 0x000000000000009E, 0x000000000000003B, 0x000000000000003A, 0x00000000000000BF, 0x0000000000000092, 0x00000000000000F0, 0x0000000000000174, 0x00000000000000C3, 0x0000000000000289, 0x0000000000000104, 0x0000000000000260, 0x000000000000004D, 0x00000000000002FB, 0x000000000000009E, 0x0000000000000191, 0x0000000000000158, 0x000000000000007D, 0x000000000000004A, 0x00000000000001E9, 0x0000000000000101, 0x00000000000000D0, 0x00000000000000FC, 0x0000000000000070, 0x000000000000011F, 0x0000000000000345, 0x0000000000000162, 0x00000000000002A4, 0x0000000000000092] |
上面有一个坑,就是取出的满足数据是123,而123这个数据在x数组中有2个,5和23,使用x.index()只能得到第一个,而满足条件的正好是后面一个,这里卡了好久,,,
得到第一个下标后,后面的所有的下标就都可以递推出来了。
部分运算过程:
1 | 157-x[5] |
过程图,手画的,hh,
1 | ans |