栈的学习理解
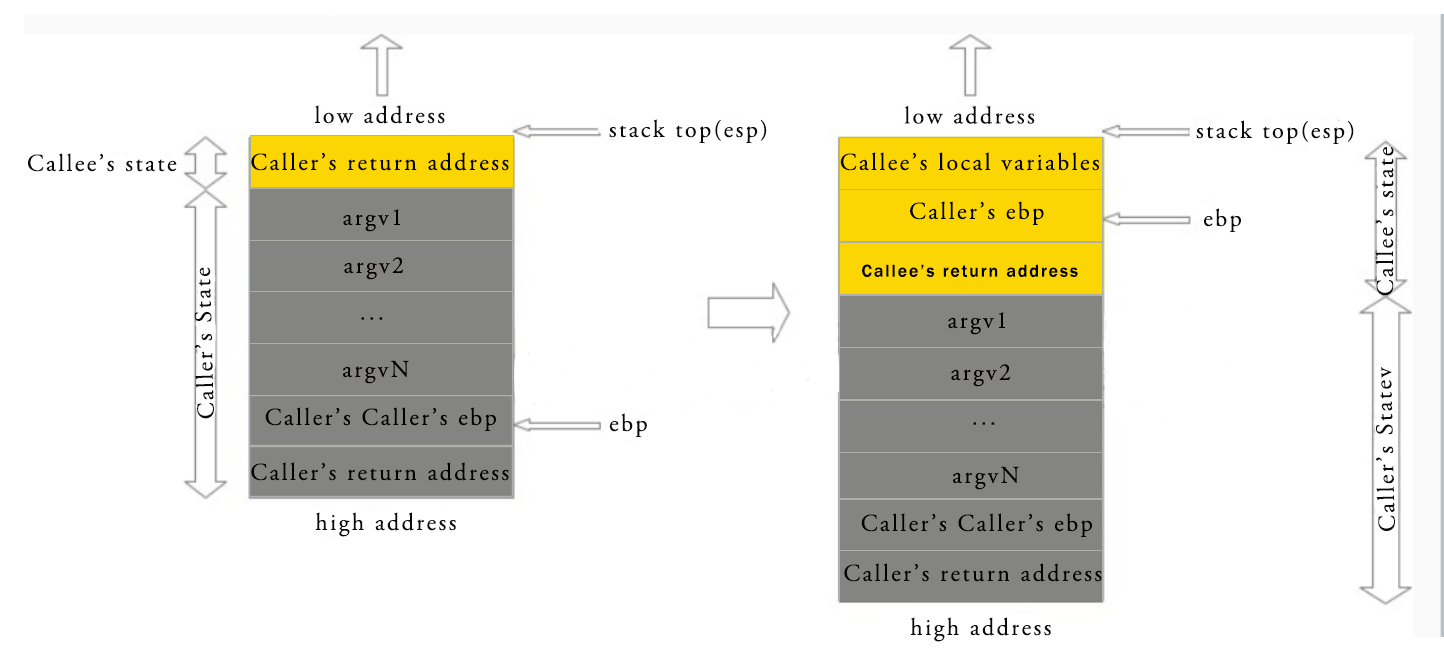
1.对于栈,主要是程序运行中保存函数的运行状态信息,参数及局部变量。发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶;函数调用结束后通过一些列指令还原调用函数的状态信息,并执行调用函数下一条指令。
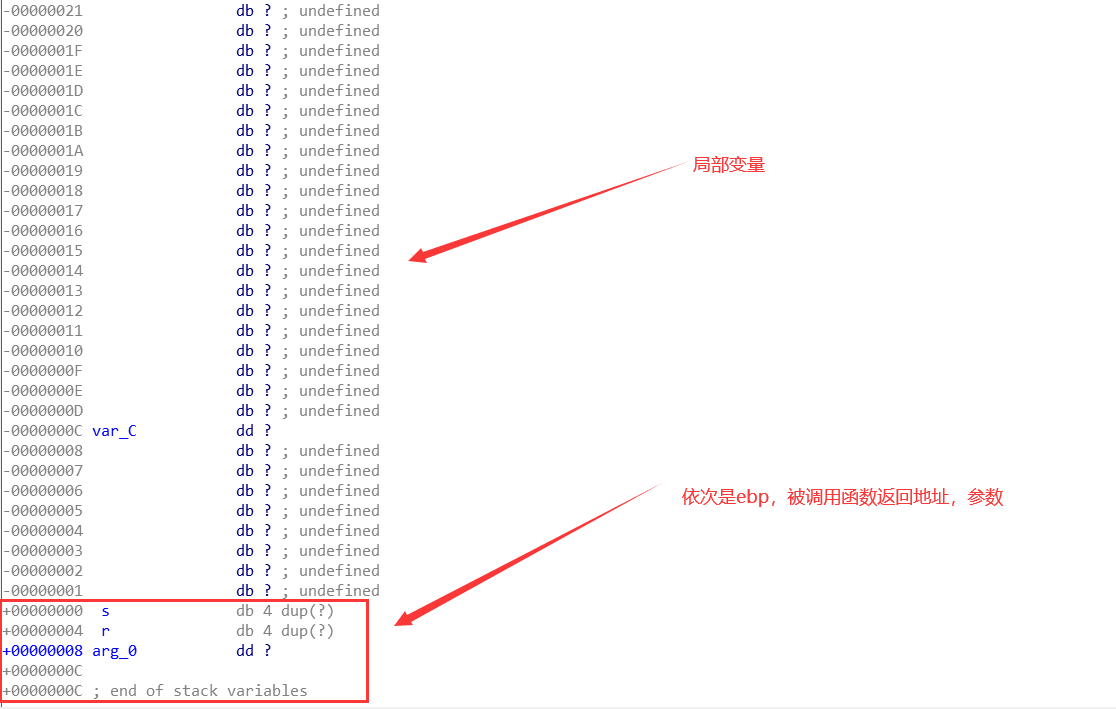
入栈顺序:1.参数 2.调用函数的下一条指令地址(通过 call)3.调用函数栈的基地址(ebp)4.被调用函数需要使用的局部变量。
2.一张图可以很清楚的表示出来。
3.在ida中看这个也很是方便。
函数调用结束后:1.先弹出局部变量(mov esp, ebp)2.接着返回调用函数的基地址(pop ebp)3.最后弹出被调用函数的返回地址(pop eip)。此时函数就接着执行被调用函数后面一条指令,再遇到函数调用也是同样的栈操作。
在看汇编中可以发现,程序在每次弹出局部变量与ebp都是使用一条指令leave,也就是 mov esp, ebp; pop ebp 的功能。
函数传参从左到右
1.函数传参都是从右向左的。如果是从左向右会怎么样呢?
2.拿经典的printf(const char *format, argv..)来假设。format最先进栈,之后是各个参数进栈,然后是被调函数的返回地址,调用函数基地址。这个时候被调函数首先肯定是要找到format,但是在它上面还有未知个数的参数,想要知道参数个数又必须找到format,要找到format又必须知道参数个数。这样以来就陷入这样的死循环。
3.当然从右往左传参就不一样了,直接加固定的esp就可以先找到format,再依次检索参数即可。
格式化字符串
1.触发格式化字符漏洞的主要函数有:printf,sprintf,fprintf。
2.printf()函数在执行时并不知道参数个数,它内部有一一个指针,用来索检格式化字符串。对于特定类型%,就去取相应参数的值,直到索检到格式化字符串结束。所以没有参数,代码也会将format string 后面的内存当做参数以16进制输出。这样就会造成内存泄露。
3.当然,规范的使用printf()等函数,还是不会问题。主要就是像gets(s);printf(s)这样的用法,使这个格式化字符串的输入权交给了我们。
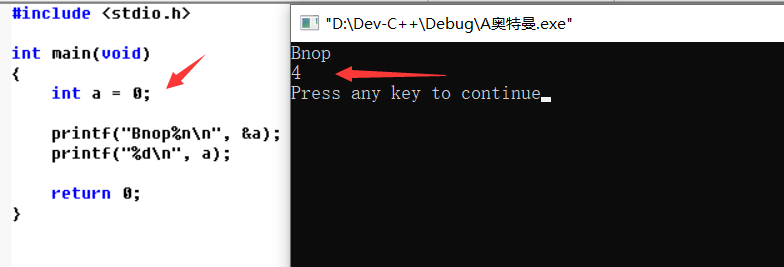
4.其中一个重要的格式化说明符,也是这个漏洞利用的关键。%xn,将我们前面已经输入的字符个数值写入后面的第x个参数的地址内。
5.一个例子可以很好的说明。
plt与got
1.他们存在实质就是为了对程序所要使用的公共函数(在动态链接库里)进行一个重定位,这就好比PE中的输入表的中的地址修正。
2.对于elf文件,它在执行一个动态库函数如printf函数时,先call printf@plt(printf@plt其实是一小段代码的首地址),然后在printf@plt这段代码中再到.got.plt中找函数实际的地址最后跳转。
3.那其实 .plt其实就是存放着所要使用函数的信息及跳转,而所有要使用的函数信息就组成了 .plt表。
4.对于.got表就是存在每个所需要的函数的实际地址,.got.plt其实是.got表的一部分。
5.所以在pwn题中,找动态库函数的实际地址时要用 elf.got[‘函数名称’];执行函数的地址用 elf.plt[‘函数地址’]。