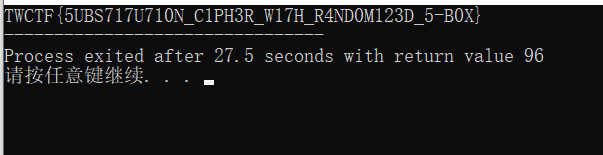
刚刚接触信息安全在攻防世界等平台刷题的部分记录,让以后来看一下开始的历程。
Misc 1 菜狗截获了一份报文。
从报文中可以联想到是md5加密,但试了一下, 发现不对。 再看报文中字母只是 a-f ,所以可能是十六进制数,又一般都是一个字节一个字符, 而一个字节存放二个十六进制数。我们就2个一组转换成十进制,但是大于了127, 可打印字符ASCII范围在0-127 , 那我们知道 }字符的ASCII十六进制为 0X7D ,再看报文最后2个字符组成的十六进制数 0xf2 ,一般我们可以有这个思路,求差值,但也有最后没有用 } 结尾的,这里就不是。但其实想到要把字符打印出来, 而字符ASCII0-127 ,那就直接试一试减128,一下子就对了,哈。
下面是C语言写的,2个一组转换成十进制数, 最后变成可打印字符:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> #include <string.h> int main (void ) char a[] = "c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2" ; int i = 0 , lenth = strlen (a), sum = 0 ; char b[100 ] = {0 }, j = 0 ; for (i = 0 ; i < lenth; i += 2 ) { if (a[i] >= 97 && a[i] <= 122 ) a[i] -= 87 ; else if (a[i] >= 65 && a[i] <= 90 ) a[i] -= 55 ; else a[i] -= 48 ; sum = sum*16 + a[i]; if (a[i+1 ]) { if (a[i+1 ] >= 97 && a[i+1 ] <= 122 ) a[i+1 ] -= 87 ; else if (a[i+1 ] >= 65 && a[i+1 ] <= 90 ) a[i+1 ] -= 55 ; else a[i+1 ] -= 48 ; sum = sum*16 + a[i+1 ]; } while (sum > 127 ) sum -= 128 ; b[j++] = sum, sum = 0 ; } puts (b); return 0 ; }
Refresh it 题目下载下来是一个.pcapng文件,先用010editor看了看会不会只是简单的将文件格式改了,因为是reverse分类的题,看了一圈,的却是流量包。
在wireshark中尝试搜索了题目关键字refresh,没有得到有用信息。又接着尝试了搜索了很多,都无果。
转到foremost和binwalk看看没有什么隐藏文件。 确实看到了2张图片,提取出来但打不开,考虑exe文件隐藏在图片文件中,查看了图片文件信息,PE文件的影子都没有。
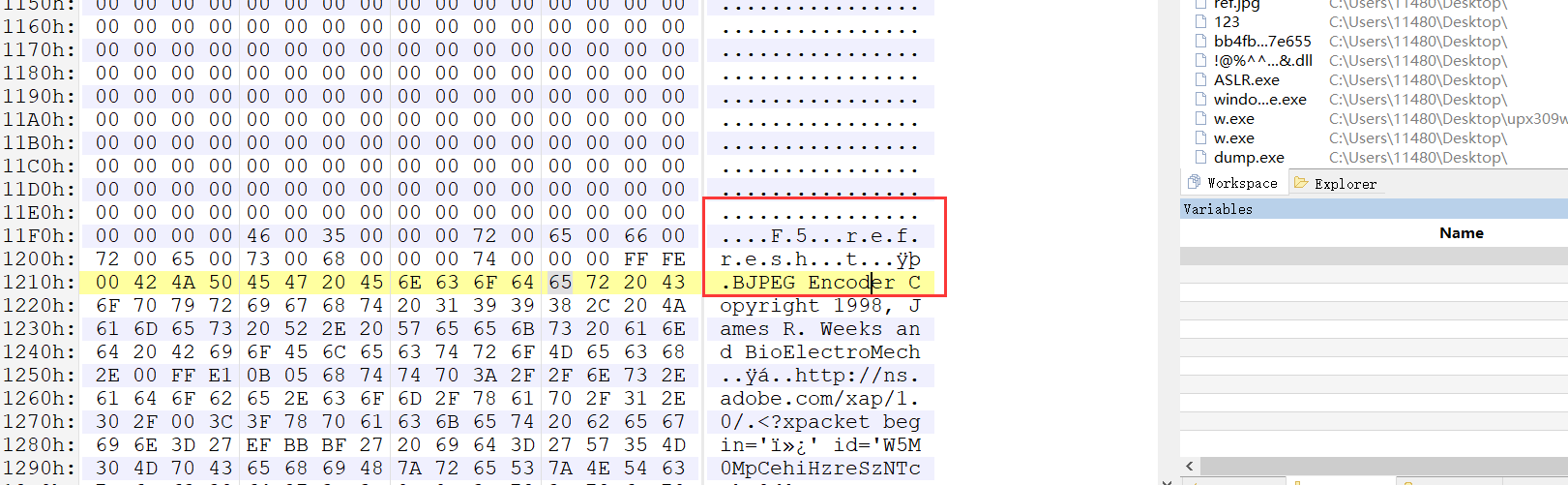
这又是过了几天来看这个题目,感觉自己找不到目标,在盲目的找…很多办法都试了下。唯一得到的就是图片。
看了看图片信息,发现F5 refrehsh。又从题目的信息,你看到刷新按钮了嘛。突然想到之前做过一个杂项题是F5-steganography隐写。后面那个的refresh猜测是密码。连忙去试了下,错误,,但是这个确实很像是考隐写。
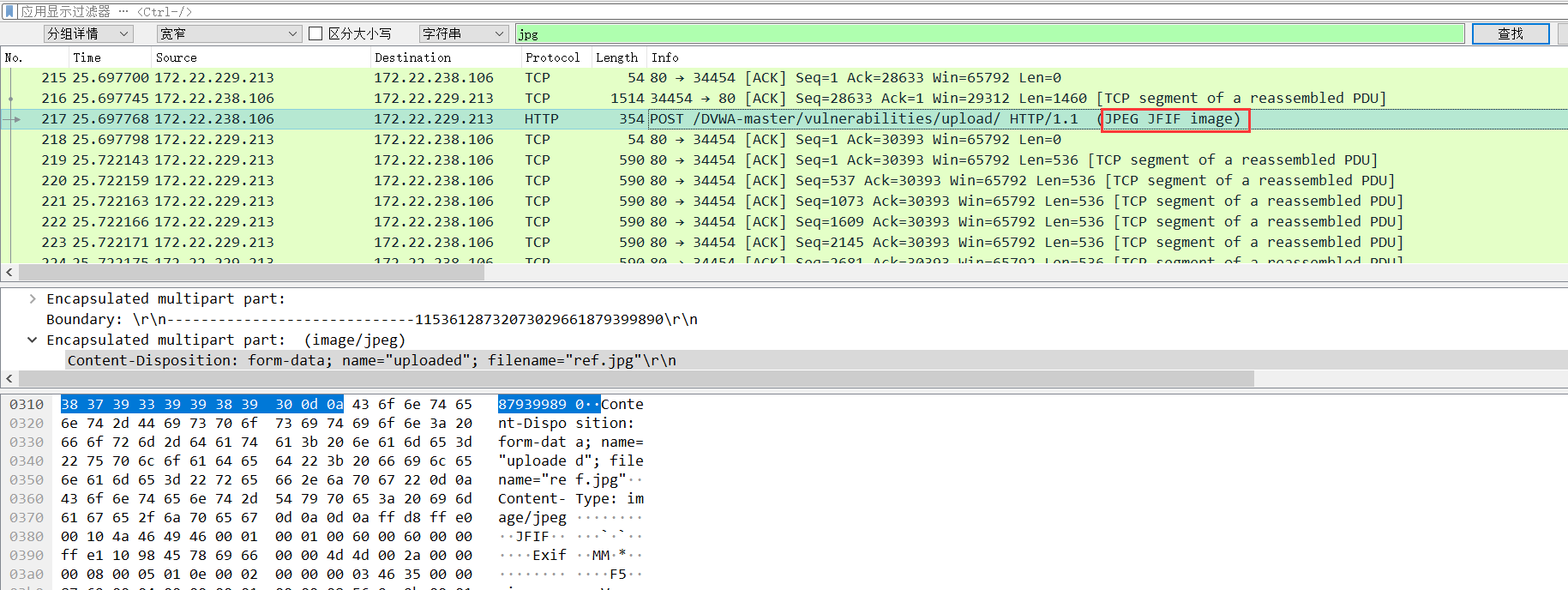
考虑是binwalk提取图片有损坏或者不全的原因,因为图片是打不开的。 又跑去wireshark。因为这次明确是找图片,直接搜索了 jpg,果然出现了个图片
追踪tcp流把图片的二进制代码复制下来,winhex重建一个文件粘贴保存.注意文件头FF D8 文件尾 FF D9
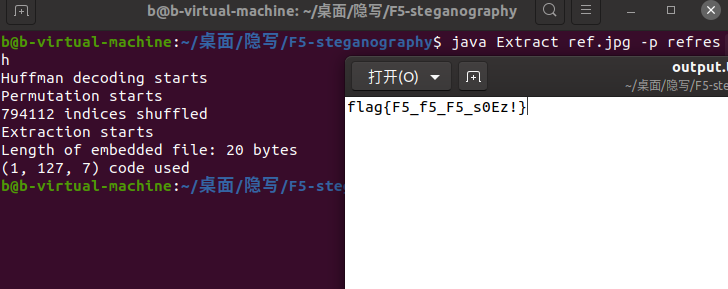
这次图片可以打开了,是个刷新按钮,再次去用F5隐写来解密。终于成功了!
花了很多时间,开始的摸索过程肯定是艰难的。另外题的提示信息太少。熟悉了一些工具的使用吧。
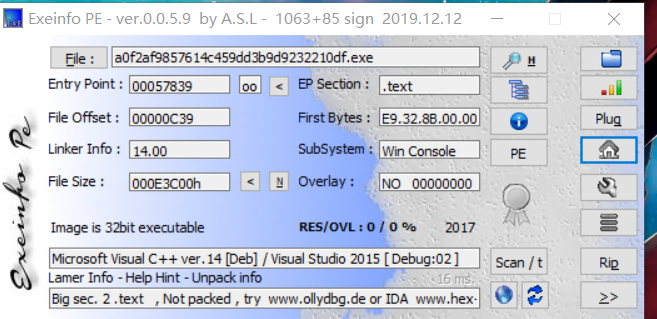
Reverse reverse1 首先拿到题, 还是拖进Exeinfope 查看一下是否有壳:
嗯没有.
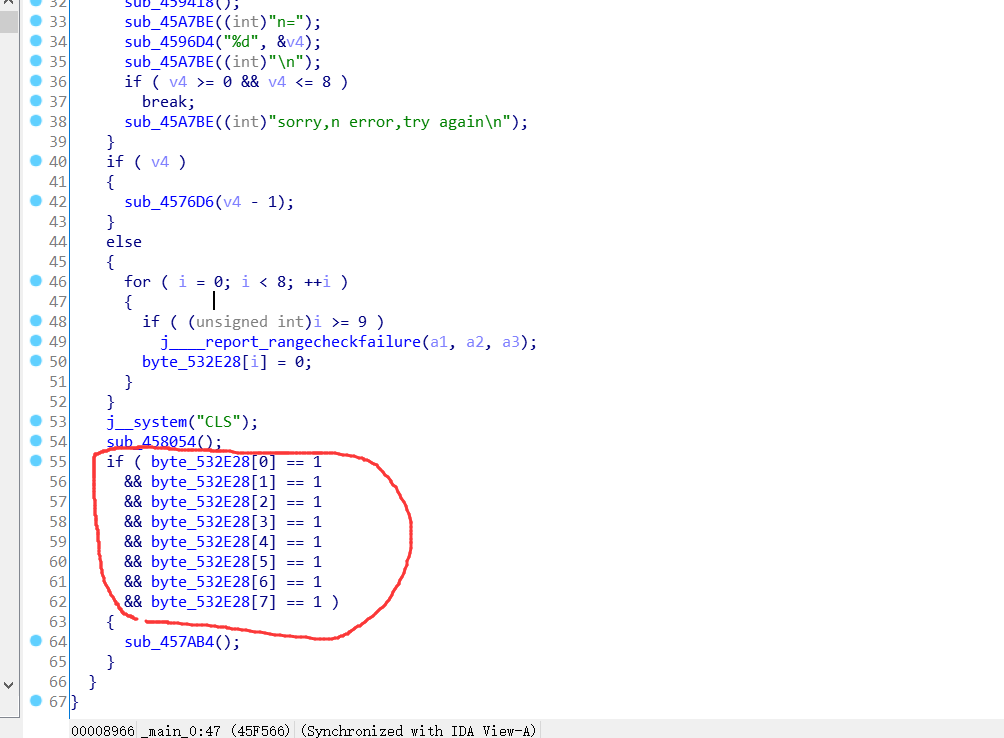
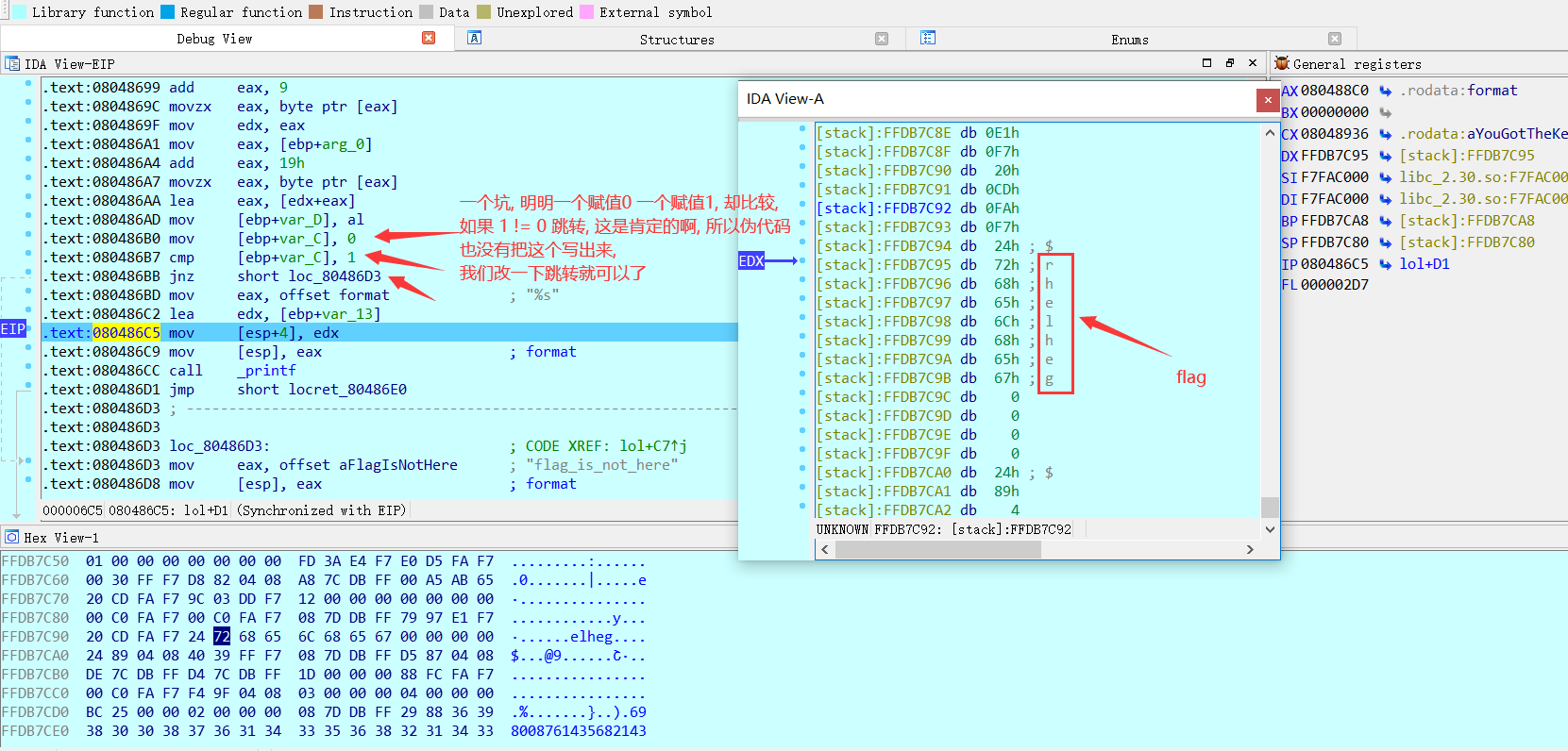
拖进ida, 找到主函数, 浏览一下程序功能, 一个游戏, 好像是通过点亮所有灯获得flag. 那么必定有一个判断条件, 往下看主函数, 显而易见:
那么下面一个函数就是关键函数了, 进去发现就是将flag计算出来, 56位长度, 还是懒得自己写程序来算.
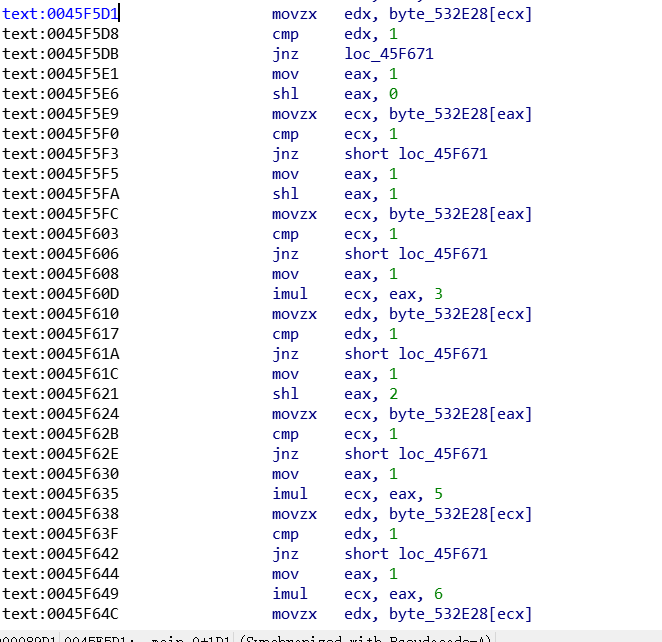
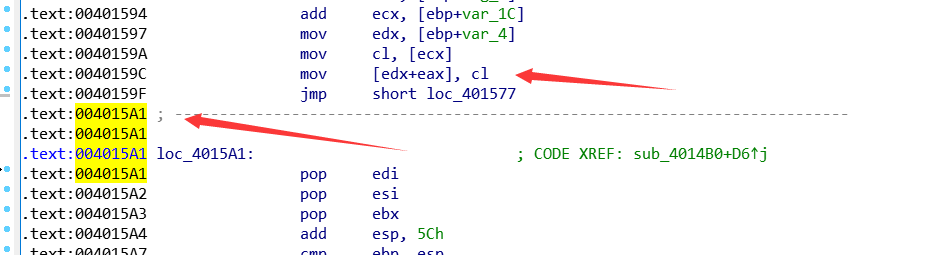
我们可以在ida中找到 判断条件 那里的的地址,: 0045F5D1
再通过OD,看加载的 VA(虚拟内存地址) :
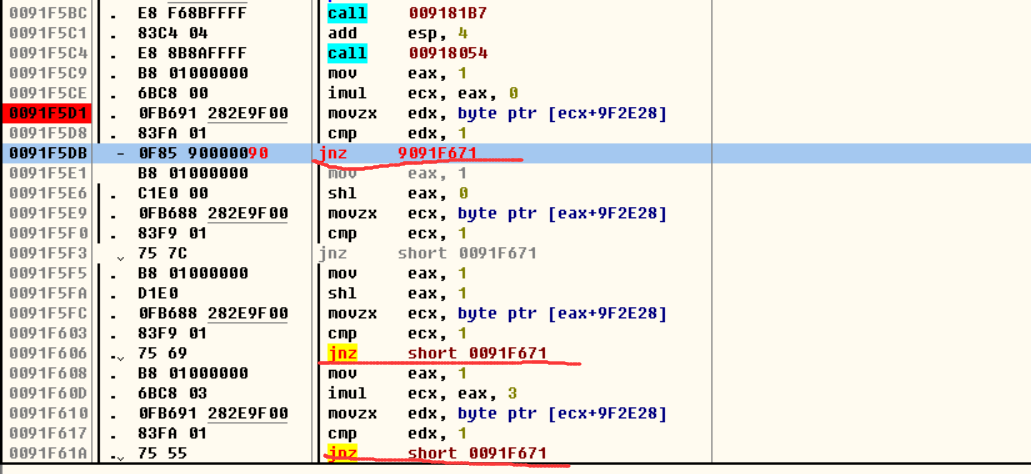
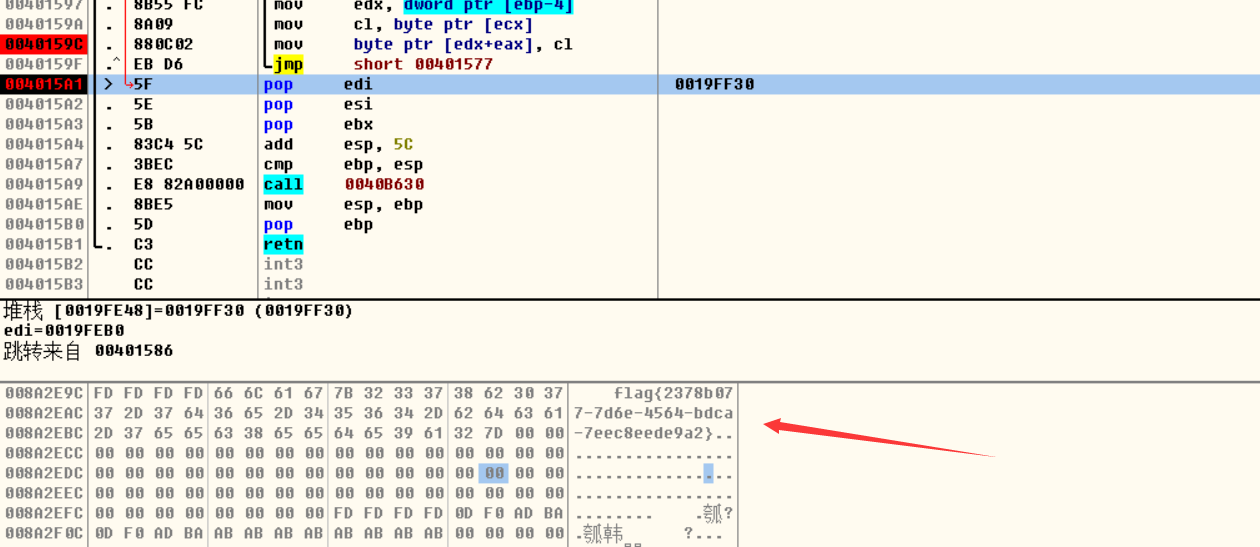
那么由于 动态和静态的VA可能不同,但是它们的RVA还是一样的。我们使用在ida中的找到VA - imagebase = RVA. 再加上OD中的VA, 即得到在OD中的地址: 0091F5D1. 这样我们直接在OD中找到这个地址: 如下图, 看到很多 jnz. 所以我们的目的是让它都不跳转, 可以每个地方都 nop了, 但我们可以往下看, 直接找到它最后应该去到的函数地址(记为A), 通过打补丁把jnz xxxx, (图中0091F5D8) 改为 jmp A.
最后一按 F9 运行, 出现 flag .
reverse2 拿到题是C源码, 直接分析就好了, 找到主函数看一下. 明确目标, 输入字符串, 也就是flag, 进行一系列操作和指定字符串比较. 找到比较的地方很容易推出:这里result == 0;
那么我们就可以知道下面函数的异或运算结果为0, 那么即发生异或运算的2个数相等.
最后就是随机数的选取了, 我们知道它是 <= 64的, 那么写一个C程序, 把所有结果打印出来, 找到符合的即可.
最后从这道题, 知道了, 1.pthread_t是unsigned long宏定义的, 8个字节整型数据.2.rand()%m也是random(m)宏定义的.
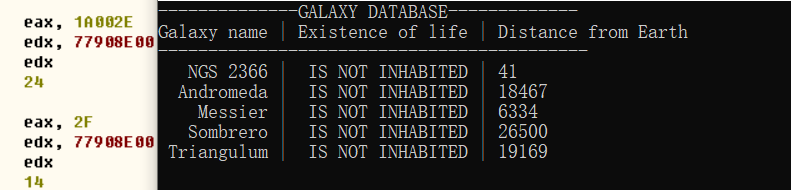
secret-galaxy-300 首先题下载下来, 发现准备了3个不同的版本, 就分析常见的PE文件. 想先打开.exe文件, 但是闪一下就退出了, 根本看不到程序是做什么的.
首先查壳, 发现无壳.😁 先用ida打开, 找到main函数.发现是从已经编码的字符串取出来, 在打印在屏幕上. 载入OD, 下断点, 看到底打印了什么: 列出几个银河; 是否是有生物存在; 它们距离地球的距离. 但这个和flag有什么关系呢.😢. 想不到联系, 回到ida中再看看.
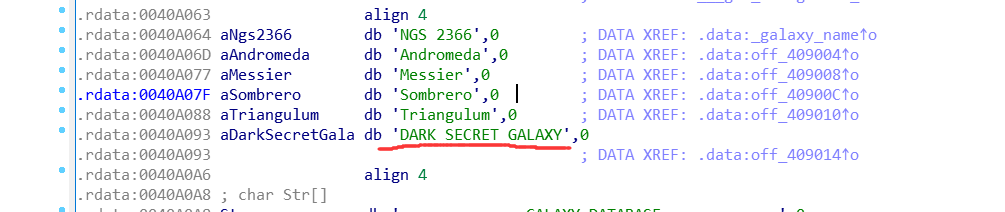
发现已经编码的字符有一个没被打印出来. 就 ctrl + x, 看哪里调用了它, 跟进去.
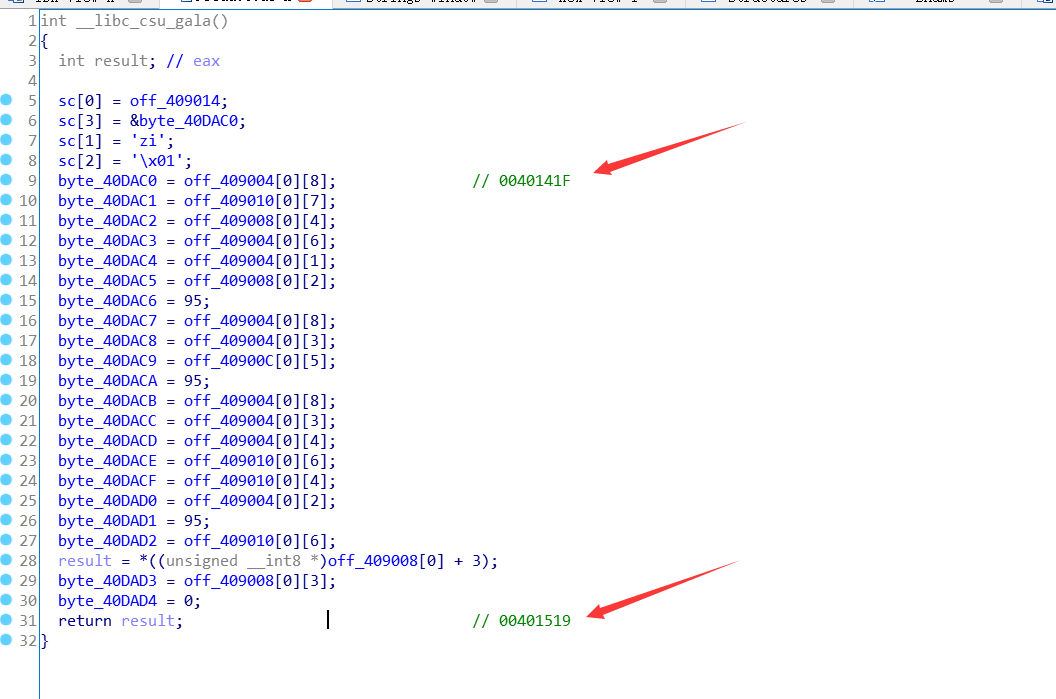
发现都是赋值操作, 且最后一个赋值0, 很可能是 flag 的字符串.记录开始和结束的地址, 去 OD 中动态调试.
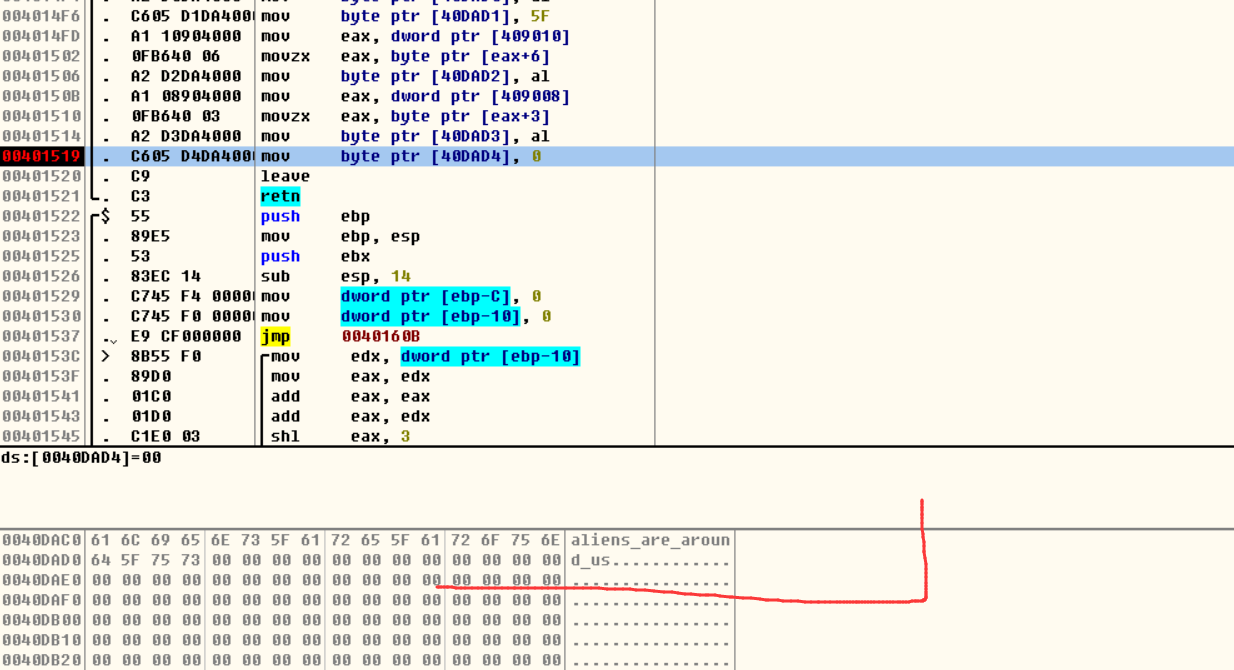
OD中在2个地址, 下断点, 并在开始记录下赋值存放数据的地址, 把它在数据窗口中跟随. F9执行出现字符串.
心得: 注意文件中编码了但是没有使用的字符串.
Newbie_calculations 首先从题目看出, 是新手计算, 想到应该和计算有关的.
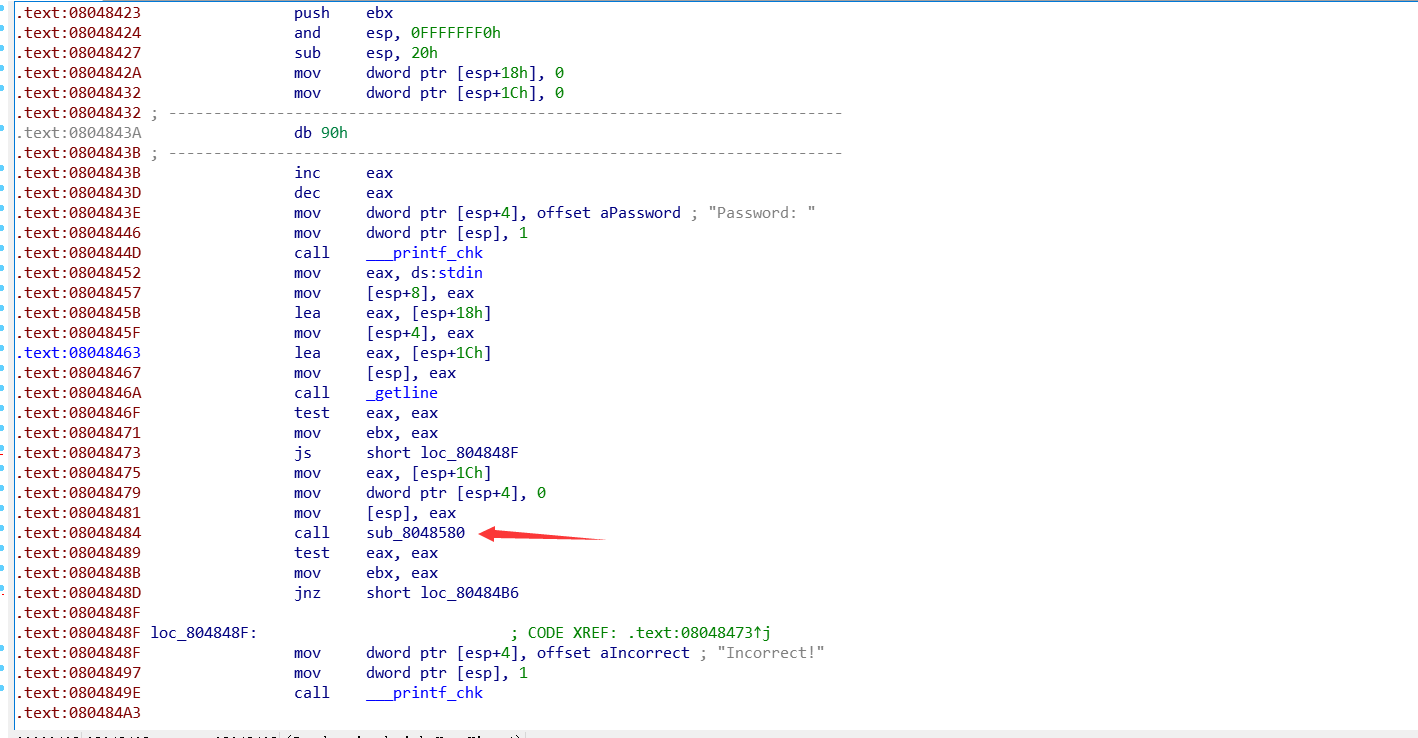
题目下载下来, 打开后, 只是打印 Your flag is: ,就卡住了, 也没有让输入信息. 在自己写C程序也遇到过这种问题, 应该是程序有什么死循环, 或者大量耗时间的算法.
载入ida, 找到main函数, 果然有很多函数, 跟进其中一个后发现 v4 = -1, 后面又用来循环, 因为自己补码不是很清楚, 开始只是想到这不是死循环嘛, 且和自己之前的想的一样. 然后天真的认为, 它可能没用, 跳过它, 直接执行后面的或许可以找到答案, 就真的去OD, 打补丁, 程序直接奔溃.
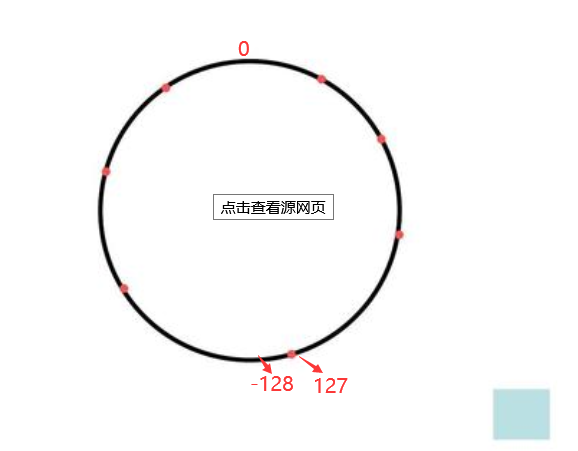
这个时候发现有很多函数, 都是一样的, 好像只有3个函数在哪里调用. 但想到麻烦,发现计算和补码相关, 然后自己写简单的程序程序复习了下补码, -1-128 = 127, 127+1 = -128; , 再结合之前看到的补码和时钟原理很像, 自己总结了下, 可以把这个计算想成是一个圆圈, 以一个字节8位来看, 我们知道范围是 -128 - 127
知道一个周期的大小是 256 . 那么有 -1+1= 0 也可以写成 -1 - 255 = 0 , 相当于 -1 逆时针转了 一圈少1的距离, 那么就是0的位置, 因为如果转了一圈的话, 回到原位置,. 顺时针加法也是一样的原理, 0 + 256 = 0 ;
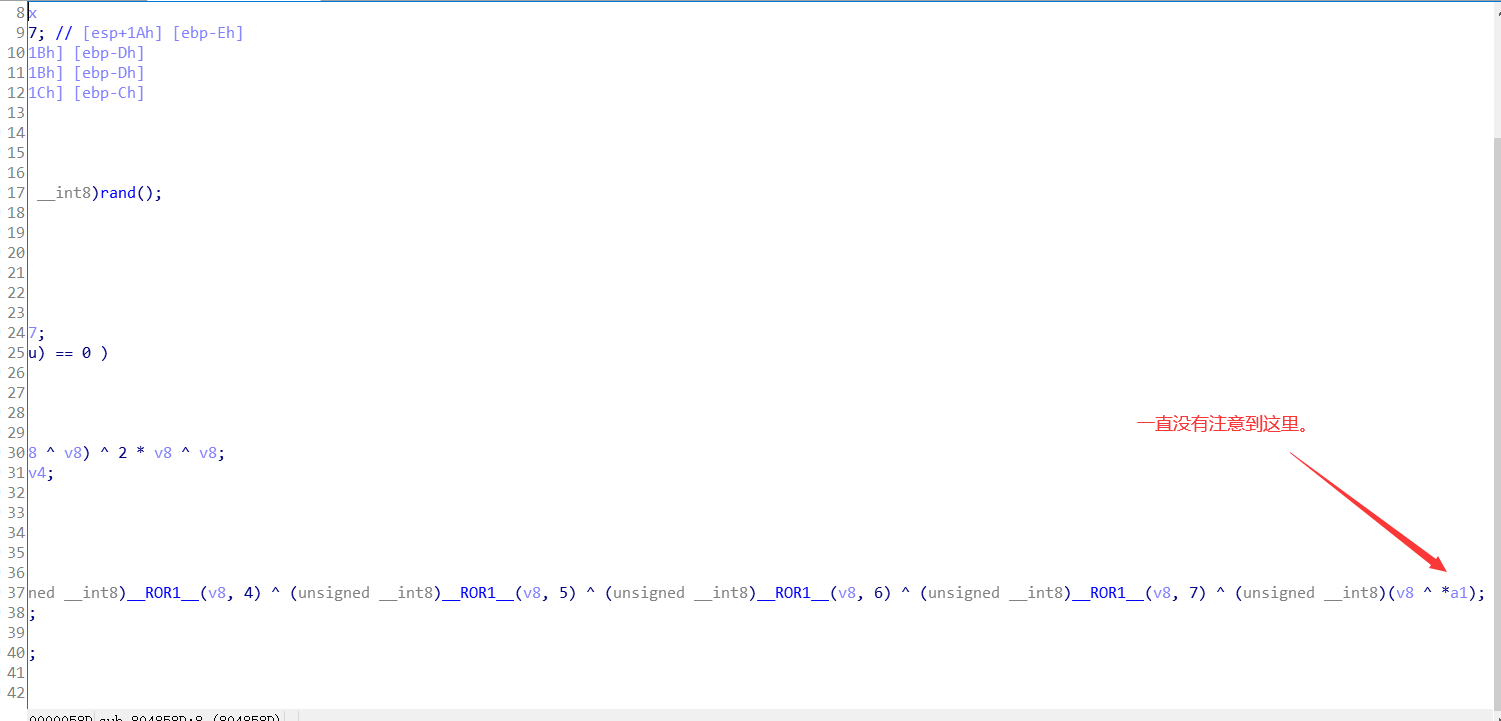
知道了这一点, 那么这道题就很容易了.要使 v4 == 0, 那么相当于 v4逆时针旋转一圈少a2的距离, 相当于 v4 += a2,
那么同样的道理, –*a 经过循环后, 相当于逆时针旋转一圈少a2的距离, 就是 *a1 += a2; 补码真的神奇.😁
后面的2个函数同理分析. 将该三个函数分别改写成对应的乘, 减, 加:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 #include <stdio.h> int *sub_401100 (int *a, int b) *a = (*a) * b; return a; } int *sub_401220 (int *a, int b) *a = (*a) - b; return a; } int *sub_401000 (int *a, int b) *a = (*a) + b; return a; } int main (void ) int *v3; int *v4; int *v5; int *v6; int *v7; int *v8; int *v9; int *v10; int *v11; int *v12; int *v13; int *v14; int *v15; int *v16; int *v17; int *v18; int *v19; int *v20; int *v21; int *v22; int *v23; int *v24; int *v25; int *v26; int *v27; int *v28; int *v29; int *v30; int *v31; int *v32; int *v33; int *v34; int *v35; int *v36; int *v37; int *v38; int *v39; int *v40; int *v41; int *v42; int *v43; int *v44; int *v45; int *v46; int *v47; int *v48; int *v49; int *v50; int *v51; int *v52; int *v53; int *v54; int *v55; int *v56; int *v57; int *v58; int *v59; int *v60; int *v61; int *v62; int *v63; int *v64; int *v65; int *v66; int *v67; int *v68; int *v69; int *v70; int *v71; int *v72; int *v73; int *v74; int *v75; int *v76; int *v77; int *v78; int *v79; int *v80; int *v81; int *v82; int *v83; int *v84; int *v85; int *v86; int *v87; int *v88; int *v89; int *v90; int *v91; int *v92; int *v93; int *v94; int *v95; int *v96; int *v97; int *v98; int *v99; int *v100; int *v101; int *v102; int *v103; int *v104; int *v105; int *v106; int *v107; int *v108; int v109; int *v110; int *v111; int v112; int *v113; int *v114; int v115; int *v116; signed int i; signed int j; int v120[32 ]; int v121; for ( i = 0 ; i < 32 ; ++i ) v120[i] = 1 ; v121 = 0 ; puts ("Your flag is:" ); v3 = sub_401100(v120, 1000000000 ); v4 = sub_401220(v3, 999999950 ); sub_401100(v4, 2 ); v5 = sub_401000(&v120[1 ], 5000000 ); v6 = sub_401220(v5, 6666666 ); v7 = sub_401000(v6, 1666666 ); v8 = sub_401000(v7, 45 ); v9 = sub_401100(v8, 2 ); sub_401000(v9, 5 ); v10 = sub_401100(&v120[2 ], 1000000000 ); v11 = sub_401220(v10, 999999950 ); v12 = sub_401100(v11, 2 ); sub_401000(v12, 2 ); v13 = sub_401000(&v120[3 ], 55 ); v14 = sub_401220(v13, 3 ); v15 = sub_401000(v14, 4 ); sub_401220(v15, 1 ); v16 = sub_401100(&v120[4 ], 100000000 ); v17 = sub_401220(v16, 99999950 ); v18 = sub_401100(v17, 2 ); sub_401000(v18, 2 ); v19 = sub_401220(&v120[5 ], 1 ); v20 = sub_401100(v19, 1000000000 ); v21 = sub_401000(v20, 55 ); sub_401220(v21, 3 ); v22 = sub_401100(&v120[6 ], 1000000 ); v23 = sub_401220(v22, 999975 ); sub_401100(v23, 4 ); v24 = sub_401000(&v120[7 ], 55 ); v25 = sub_401220(v24, 33 ); v26 = sub_401000(v25, 44 ); sub_401220(v26, 11 ); v27 = sub_401100(&v120[8 ], 10 ); v28 = sub_401220(v27, 5 ); v29 = sub_401100(v28, 8 ); sub_401000(v29, 9 ); v30 = sub_401000(&v120[9 ], 0 ); v31 = sub_401220(v30, 0 ); v32 = sub_401000(v31, 11 ); v33 = sub_401220(v32, 11 ); sub_401000(v33, 53 ); v34 = sub_401000(&v120[10 ], 49 ); v35 = sub_401220(v34, 2 ); v36 = sub_401000(v35, 4 ); sub_401220(v36, 2 ); v37 = sub_401100(&v120[11 ], 1000000 ); v38 = sub_401220(v37, 999999 ); v39 = sub_401100(v38, 4 ); sub_401000(v39, 50 ); v40 = sub_401000(&v120[12 ], 1 ); v41 = sub_401000(v40, 1 ); v42 = sub_401000(v41, 1 ); v43 = sub_401000(v42, 1 ); v44 = sub_401000(v43, 1 ); v45 = sub_401000(v44, 1 ); v46 = sub_401000(v45, 10 ); sub_401000(v46, 32 ); v47 = sub_401100(&v120[13 ], 10 ); v48 = sub_401220(v47, 5 ); v49 = sub_401100(v48, 8 ); v50 = sub_401000(v49, 9 ); sub_401000(v50, 48 ); v51 = sub_401220(&v120[14 ], 1 ); v52 = sub_401100(v51, -294967296 ); v53 = sub_401000(v52, 55 ); sub_401220(v53, 3 ); v54 = sub_401000(&v120[15 ], 1 ); v55 = sub_401000(v54, 2 ); v56 = sub_401000(v55, 3 ); v57 = sub_401000(v56, 4 ); v58 = sub_401000(v57, 5 ); v59 = sub_401000(v58, 6 ); v60 = sub_401000(v59, 7 ); sub_401000(v60, 20 ); v61 = sub_401100(&v120[16 ], 10 ); v62 = sub_401220(v61, 5 ); v63 = sub_401100(v62, 8 ); v64 = sub_401000(v63, 9 ); sub_401000(v64, 48 ); v65 = sub_401000(&v120[17 ], 7 ); v66 = sub_401000(v65, 6 ); v67 = sub_401000(v66, 5 ); v68 = sub_401000(v67, 4 ); v69 = sub_401000(v68, 3 ); v70 = sub_401000(v69, 2 ); v71 = sub_401000(v70, 1 ); sub_401000(v71, 20 ); v72 = sub_401000(&v120[18 ], 7 ); v73 = sub_401000(v72, 2 ); v74 = sub_401000(v73, 4 ); v75 = sub_401000(v74, 3 ); v76 = sub_401000(v75, 6 ); v77 = sub_401000(v76, 5 ); v78 = sub_401000(v77, 1 ); sub_401000(v78, 20 ); v79 = sub_401100(&v120[19 ], 1000000 ); v80 = sub_401220(v79, 999999 ); v81 = sub_401100(v80, 4 ); v82 = sub_401000(v81, 50 ); sub_401220(v82, 1 ); v83 = sub_401220(&v120[20 ], 1 ); v84 = sub_401100(v83, -294967296 ); v85 = sub_401000(v84, 49 ); sub_401220(v85, 1 ); v86 = sub_401220(&v120[21 ], 1 ); v87 = sub_401100(v86, 1000000000 ); v88 = sub_401000(v87, 54 ); v89 = sub_401220(v88, 1 ); v90 = sub_401000(v89, 1000000000 ); sub_401220(v90, 1000000000 ); v91 = sub_401000(&v120[22 ], 49 ); v92 = sub_401220(v91, 1 ); v93 = sub_401000(v92, 2 ); sub_401220(v93, 1 ); v94 = sub_401100(&v120[23 ], 10 ); v95 = sub_401220(v94, 5 ); v96 = sub_401100(v95, 8 ); v97 = sub_401000(v96, 9 ); sub_401000(v97, 48 ); v98 = sub_401000(&v120[24 ], 1 ); v99 = sub_401000(v98, 3 ); v100 = sub_401000(v99, 3 ); v101 = sub_401000(v100, 3 ); v102 = sub_401000(v101, 6 ); v103 = sub_401000(v102, 6 ); v104 = sub_401000(v103, 6 ); sub_401000(v104, 20 ); v105 = sub_401000(&v120[25 ], 55 ); v106 = sub_401220(v105, 33 ); v107 = sub_401000(v106, 44 ); v108 = sub_401220(v107, 11 ); sub_401000(v108, 42 ); sub_401000(&v120[26 ], v120[25 ]); sub_401000(&v120[27 ], v120[12 ]); v109 = v120[27 ]; v110 = sub_401220(&v120[28 ], 1 ); v111 = sub_401000(v110, v109); sub_401220(v111, 1 ); v112 = v120[23 ]; v113 = sub_401220(&v120[29 ], 1 ); v114 = sub_401100(v113, 1000000 ); sub_401000(v114, v112); v115 = v120[27 ]; v116 = sub_401000(&v120[30 ], 1 ); sub_401100(v116, v115); sub_401000(&v120[31 ], v120[30 ]); printf ("CTF{" ); for ( j = 0 ; j < 32 ; ++j ) printf ("%c" , (v120[j])); printf ("}\n" ); return 0 ; }
reverse-for-the-holy-grail-350 又是C++的题, 对于初学, 我看这个有些还是很吃力的, 有些函数功能连蒙带猜. 其实静下心来分析, 逻辑还是很简单.
找到关键函数进去后, 看起来很多, 但逻辑也是不难的.
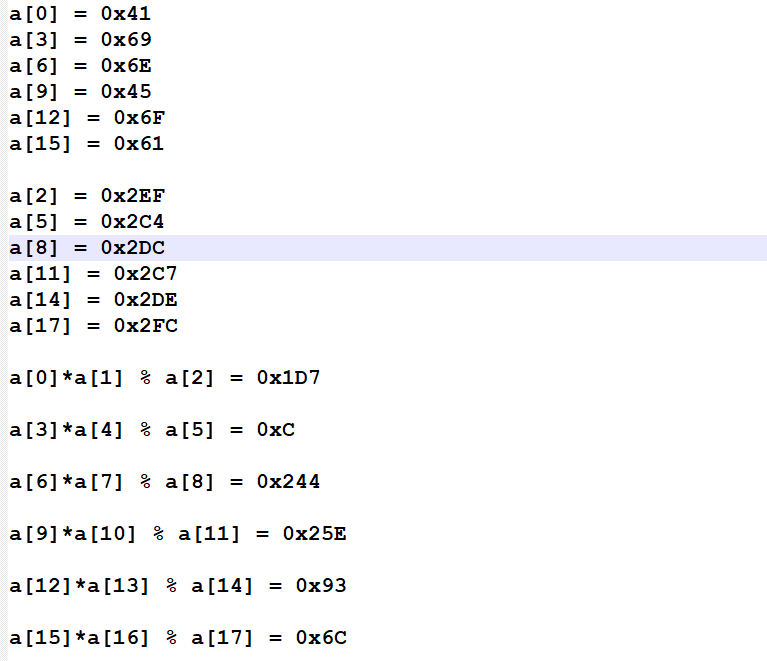
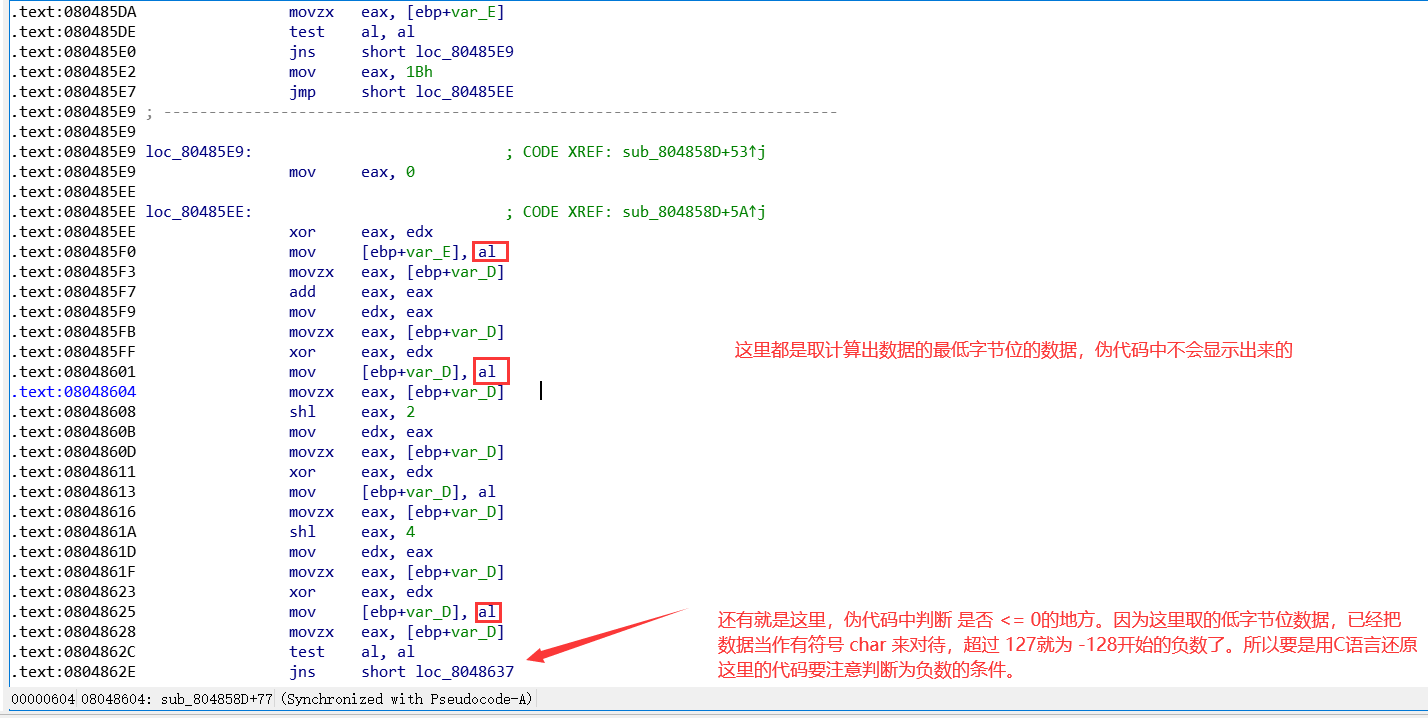
这是程序的算法, 我挨个记录了下来……..我在到这步的时候, 就是在纠结那个取余多解的问题, 想到算起来很烦, 但由于是可输入的字符, 我们用遍历即可 (0-127)
最后附上, 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> int main (void ) int first[] = {0x41 , 0x69 , 0x6e , 0x45 , 0x6f , 0x61 }; int second[] = {0x2ef , 0x2c4 , 0x2dc , 0x2c7 , 0x2de , 0x2fc }; int third[] = {0x1d7 , 0xc , 0x244 , 0x25e , 0x93 , 0x6c }; int mod[18 ] = {0 }; int i = 0 , n = 666 , j = 0 , z = 0 ; int flag[20 ] = {0 }; for (i = 0 ; i < 18 ; i++) { mod[i] = n; n += n%5 ; } for (i = 0 ; i < 18 ; i += 3 ) { flag[i] = first[j]; flag[i+2 ] = second[j] ^ mod[i+2 ]; for (z = 0 ; z < 127 ; z++) { if ((flag[i] ^ mod[i])*(z^mod[i+1 ]) % second[j] == third[j]) { flag[i+1 ] = z; break ; } } j++; } for (i = 0 ; i < 18 ; i++) printf ("%c" , flag[i]); return 0 ; }
总结: 程序中注意看清传入参数时,是一个字节, 还是一个int类型(4个字节); 取余运算, 逆向时, 一般遍历即可.
elrond32 首先, 下载下来, 用ida打开, 发现没有输入的地方. 或许是隐藏起来了. 就在linux中运行一下来看, 果然没有输入, 只是输出验证失败.
回到ida, 逻辑也很清楚, 就是一个函数的返回值 非0 即可, 进入关键函数: 也很简单, 就是一个递归调用. 从0开始, 每次 (a1) 都符合相应的值且最要最后的跳出递归即可.通过这个我们就知道了 a1数组的值. 算了一下 a2的值为: 0 7 1 3 6 5 9 4 2, 而2没有就跳出. 按照这个顺序取 (a1) .
其实浏览程序的时候, 已经看过 验证通过下面的一个函数, 就是让33个已经编码了的字符与我们得到的 (a1)异或运算, 再打印出flag. 下面C代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> int main (void ) char a[] = {105 , 115 , 101 , 110 , 103 , 97 , 114 , 100 }; union { char b[1000 ]; int n[33 ]; }A = { 15 , 0 , 0 , 0 , 31 , 0 , 0 , 0 , 4 , 0 , 0 , 0 , 9 , 0 , 0 , 0 , 28 , 0 , 0 , 0 , 18 , 0 , 0 , 0 , 66 , 0 , 0 , 0 , 9 , 0 , 0 , 0 , 12 , 0 , 0 , 0 , 68 , 0 , 0 , 0 , 13 , 0 , 0 , 0 , 7 , 0 , 0 , 0 , 9 , 0 , 0 , 0 , 6 , 0 , 0 , 0 , 45 , 0 , 0 , 0 , 55 , 0 , 0 , 0 , 89 , 0 , 0 , 0 , 30 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 89 , 0 , 0 , 0 , 15 , 0 , 0 , 0 , 8 , 0 , 0 , 0 , 28 , 0 , 0 , 0 , 35 , 0 , 0 , 0 , 54 , 0 , 0 , 0 , 7 , 0 , 0 , 0 , 85 , 0 , 0 , 0 , 2 , 0 , 0 , 0 , 12 , 0 , 0 , 0 , 8 , 0 , 0 , 0 , 65 , 0 , 0 , 0 , 10 , 0 , 0 , 0 , 20 , 0 , 0 , 0 }; char flag[100 ] = {0 }; int i = 0 ; for (i = 0 ; i <= 32 ; i++) putchar (A.n[i] ^ a[i % 8 ]); return 0 ; }
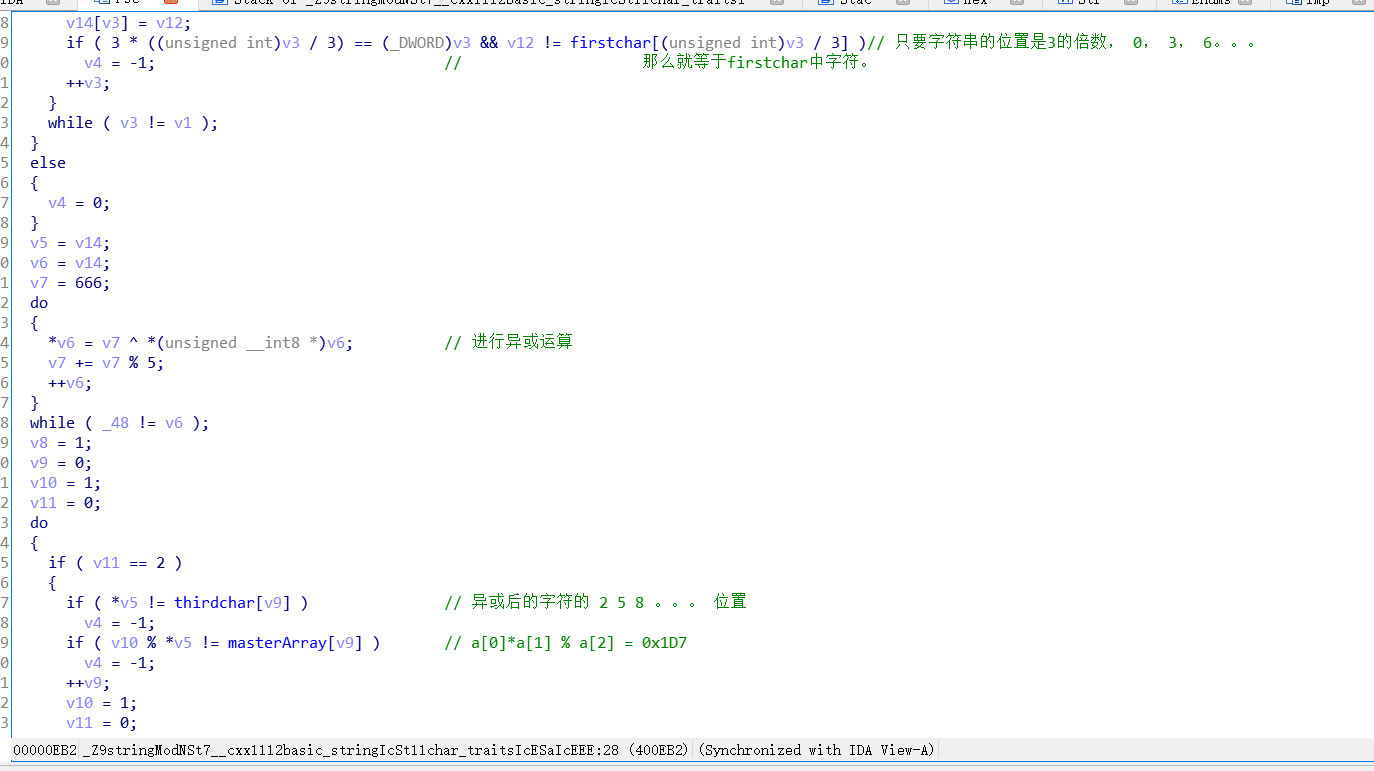
百越杯2018-crazy 首先,这道题的算法很简单,就是考引用C++的字符串类的函数。 但是自己也挖掘了一些感觉有用的东西,主要是通过这道题总结 c++字符串类。
拖入ExeinfoPe,题目是64为elf文件,用64为ida打开。
找到主函数, 查看伪代码,发现很冗长,但大多数都是那些字符串类函数和无用的信息。 我们可以先通过点击最后比较要用到的字符串的名称,这时会把所有相同名称都高亮显示出来,就可以通过逻辑判断出那些是关键函数和变量。
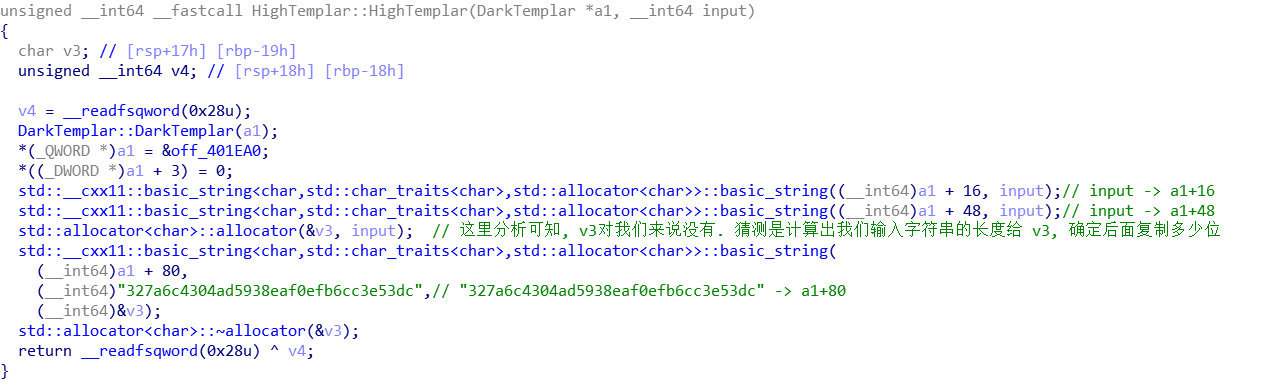
第一个关键函数 HighTemplar::HighTemplar((DarkTemplar *)&v23,(__int64)&input);
第二个关键函数 HighTemplar::calculate((HighTemplar *)&v23);
第三个关键函数 HighTemplar::getSerial((HighTemplar *)&v23)
最后wp:但是要引起注意的是这个flag真的奇怪,开始以为算错了,检查几遍,最后就是这个 tMx~qdstOs~crvtwb~aOba}qddtbrtcd 再加上flag{}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <string.h> int main (void ) char a[] = "327a6c4304ad5938eaf0efb6cc3e53dc" ; int i = 0 ; char flag[100 ] = {0 }; for (i = 0 ; i < strlen (a); i++) { a[i] = (a[i] - 11 ) ^ 0x13 ; a[i] = (a[i] - 23 ) ^ 0x50 ; } puts (a); return 0 ; }
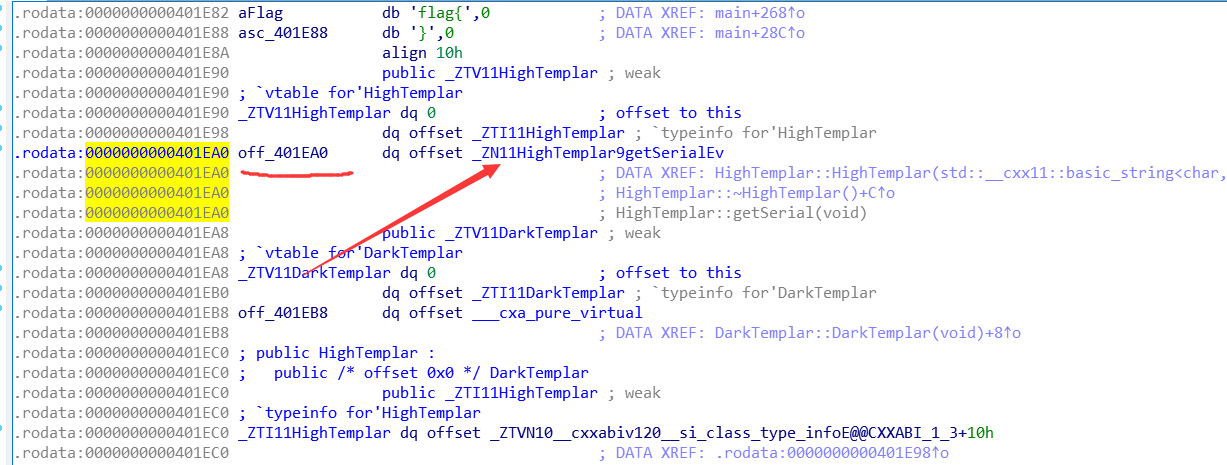
总结: 先说一下做这个题想过的一个问题。 我们知道 rodata 段是只读的,存放常量等,但是这里却有字符串地址的赋值,他把 0x401EA0 地址的值改变了,但为什么可以这样呢,查了资料,也想了很久,最后认为应该是存放的指针,而且我们可以看到这一段都是8字节的增加,都是一个指针 8字节的大小。
这里也通过查资料,知道了以前学习指针的疑问。
因为我们初始化一个数组时,数组的初始值放在rodata段里面。数组对应开辟的空间上的数值存放在栈上,编译器会去访问rodata段上的初始值然后取来初始化局部变量,因此数组的值才能修改。 而指针指向的是rodata段,是不能被修改的 。
第二个就是通过c++官方手册的查询对各种c++引用的各种字符串的总结。 下面的 a b 为字符数组。
std::__cxx11::basic_string<char,std::char_traits,std::allocator>::operator 即 a[i] 的意思,如果operator后面没有 [] ,那就是 a+i std::__cxx11::basic_string<char,std::char_traits,std::allocator>::basic_string(a,b,lenth) 即 strncpy(a,b,lenth) 第三个参数可选 std::allocator::~allocator(a) 发现只要前面有个 ~ 的都是释放 。 即 free(a) std::__cxx11::basic_string<char,std::char_traits,std::allocator>::length(a) 即 strlen(a) std::operator<<<std::char_traits>(&std::cout,”hello”) 后面总跟着下面一句。 关键是count std::ostream::operator<<(v1,(__int64)&std::endl<char,std::char_traits>) 即 printf(“hello”) std::operator>><char,std::char_traits,std::allocator>(&std::cin,&a) 关键是in 即 gets(a)
easyCpp C++逆向的题,刚开始接触很多代码看不懂,感觉可读性低。 但是看多了,还是会好很多。 是一个慢慢熟悉stl的过程吧。
经过了一些CPP逆向题的折磨,这个题大多数函数连懵带猜的看起来还好,但是遇到了一个不仔细的错误,想了很久。。。。。
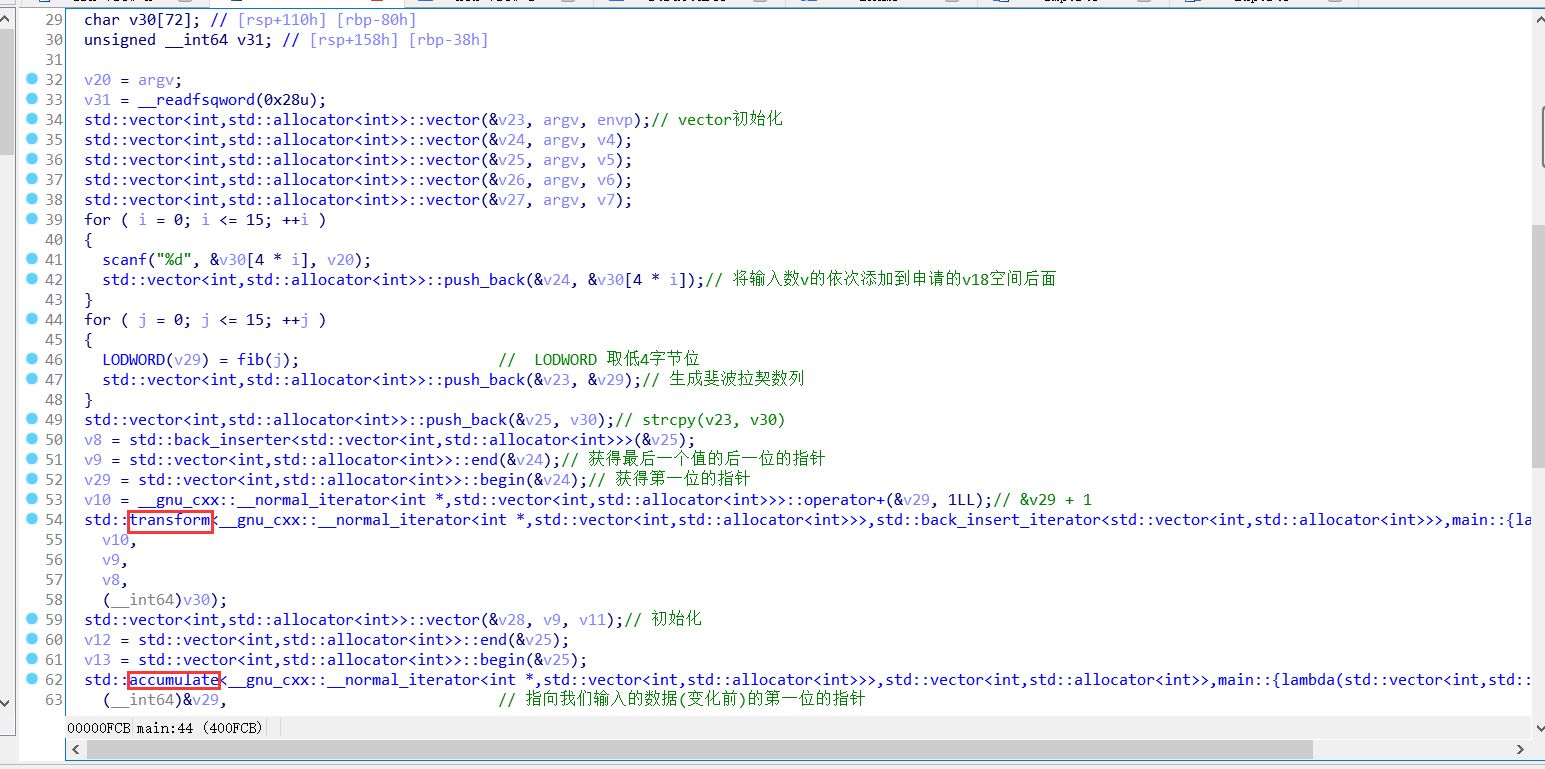
64位elf文件,载入ida,函数的大部分还是看懂了。 2个关键函数。 transform accumulate
先进入 transform。 算法也是很简单,就是函数读起来更麻烦。
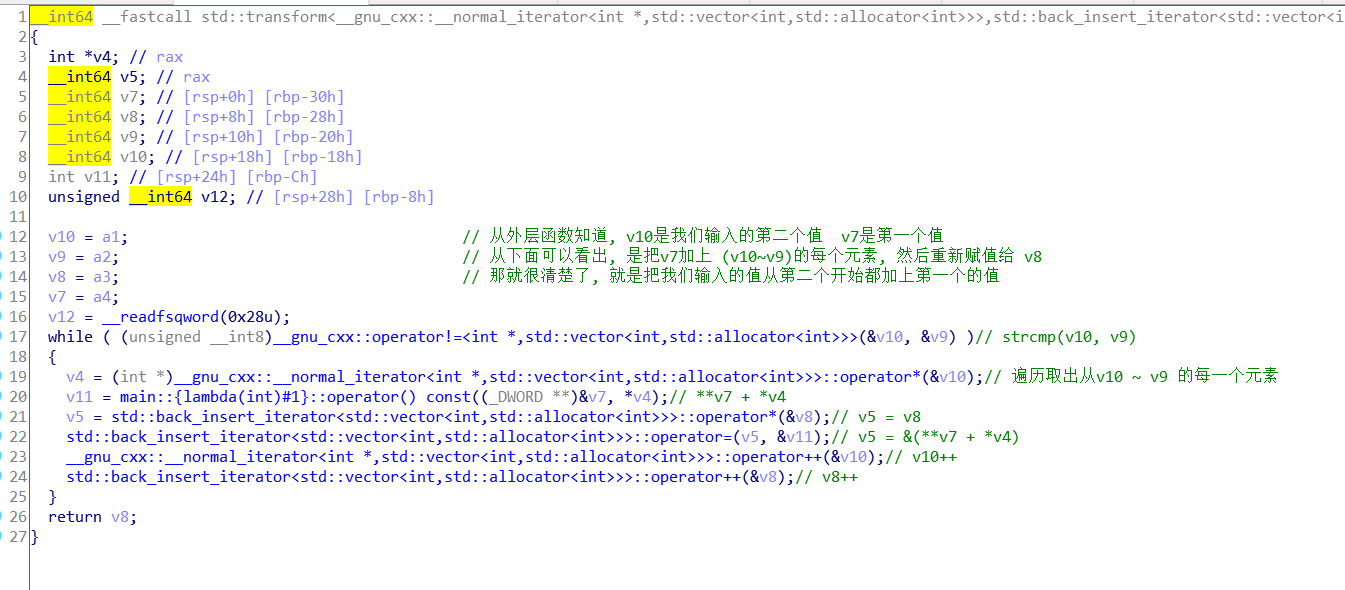
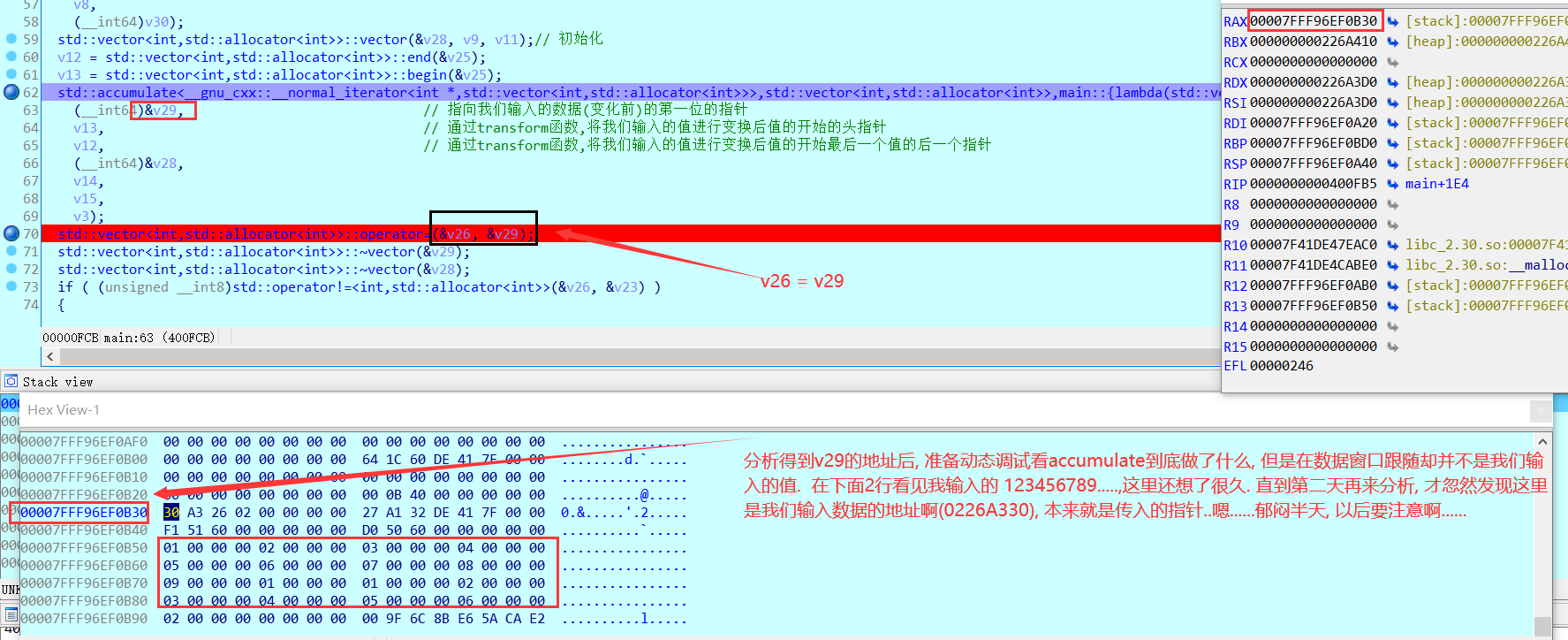
下面 accumulate。 这个看起来就不是那么容易了,有很多地址传过来传过去就很混淆。 那就ida动态调试看看这个函数是做什么。(也是这里自己想了很久的错误,虽然很简单的,可能是stl把自己搞昏了吧)。
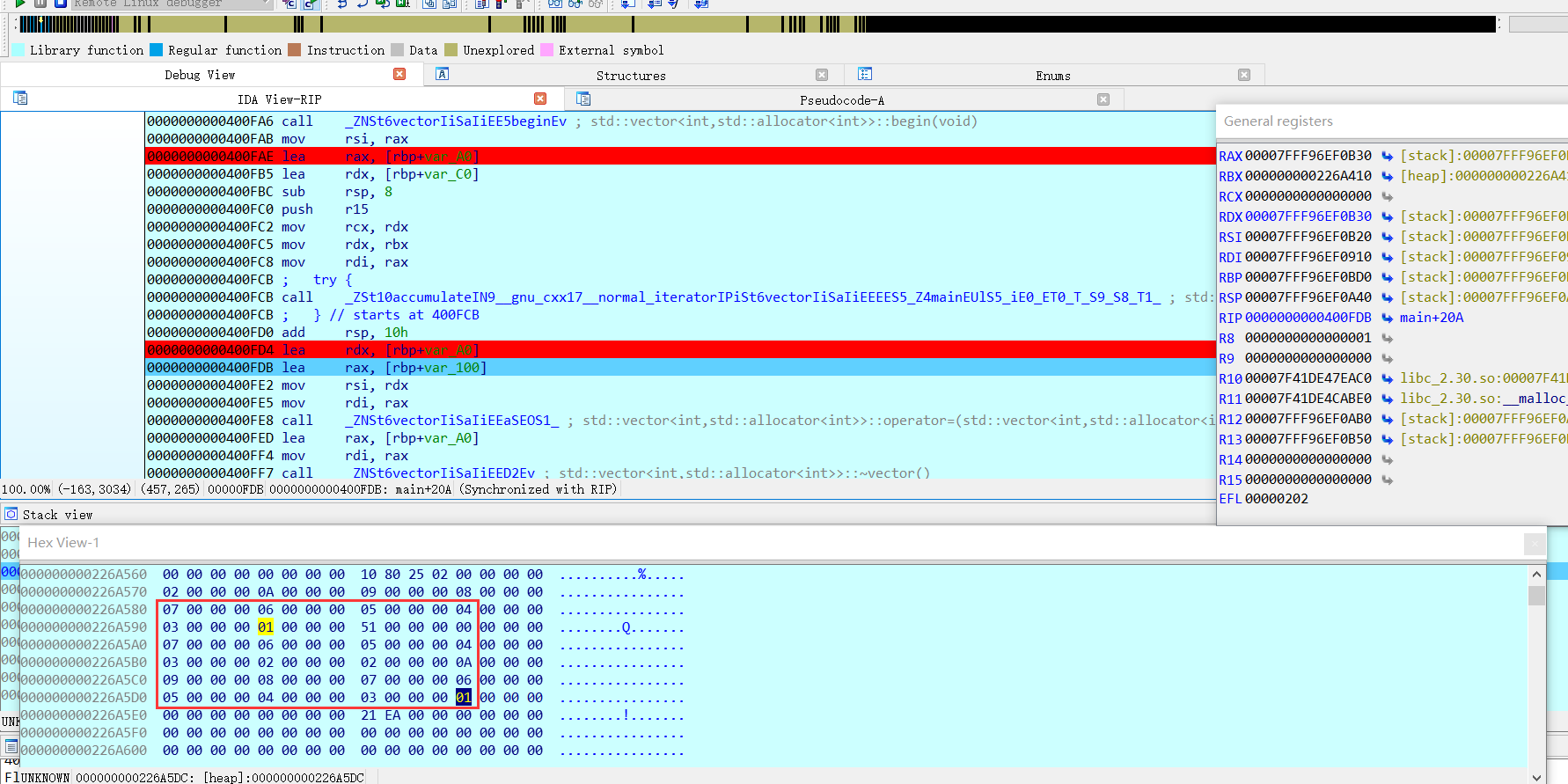
发现错误,重新调试后得到经过 accumulate 函数后的结果。 把结果都记录下来后。 发现只是把 transform函数后的结果进行了逆序。
开始写 exp: 得到 987 -377 -610 -754 -843 -898 -932 -953 -966 -974 -979 -982 -984 -985 -986 -986 。 最后在linux下运行程序输入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <stdio。h> int fib (int a) if (!a || a == 1 ) return 1 ; return fib(a-1 ) + fib(a-2 ); } int main (void ) int flag[100 ] = {0 }, i = 0 ; for (i = 0 ; i <= 15 ; i++) { flag[i] = fib(i); } for (i = 15 ; i >= 0 ; i--) { printf ("%d " , flag[i] = (i < 15 ? flag[i] - flag[15 ]:flag[i])); } return 0 ; }
总结:注意传递的参数是指针还是值。
Windows_Reverse2 首先,因为是个.exe文件, 先打开看一下程序是做什么的, 出现 input code: 也就是让我们输入一个密码验证.
用ida打开, 还是先 shift + 12 搜索一下字符串, 然而并没有发现我们打开程序看到的 *input code: * ,并且程序函数也很少, 那就是加壳了的. 开始也忘了用软件查一下壳.
那么用OD打开, 使用堆栈平衡的方法, 找到程序的 OEP, 然后dump, 但是注意改一下加载的初始地址和入口点, 这个程序并不是 0x400000开始, 每次加载都是不一样的地址,应该是 ASLR保护技术吧, 之前有了解过一些.通过内存窗口, 知道了是 0x1F0000.<!–
dump出后,但是打不开, 之前学习脱壳时了解过,但是没有实践. 就去下载import rec ,但打开找不到桌面的文件, 试了好几个也不行, 百度也无果. 也不想用脱壳软件,主要想操作一下. 其实对于去ida反编译已经足够了,因为那个只是会影响动态链接的函数.
ida再次打开后, 找到主函数, 转换为伪代码, 逻辑很简单, 就是把我们输入的字符先进行判断,然后进行加密,与编码的字符对比. 先看判断函数.
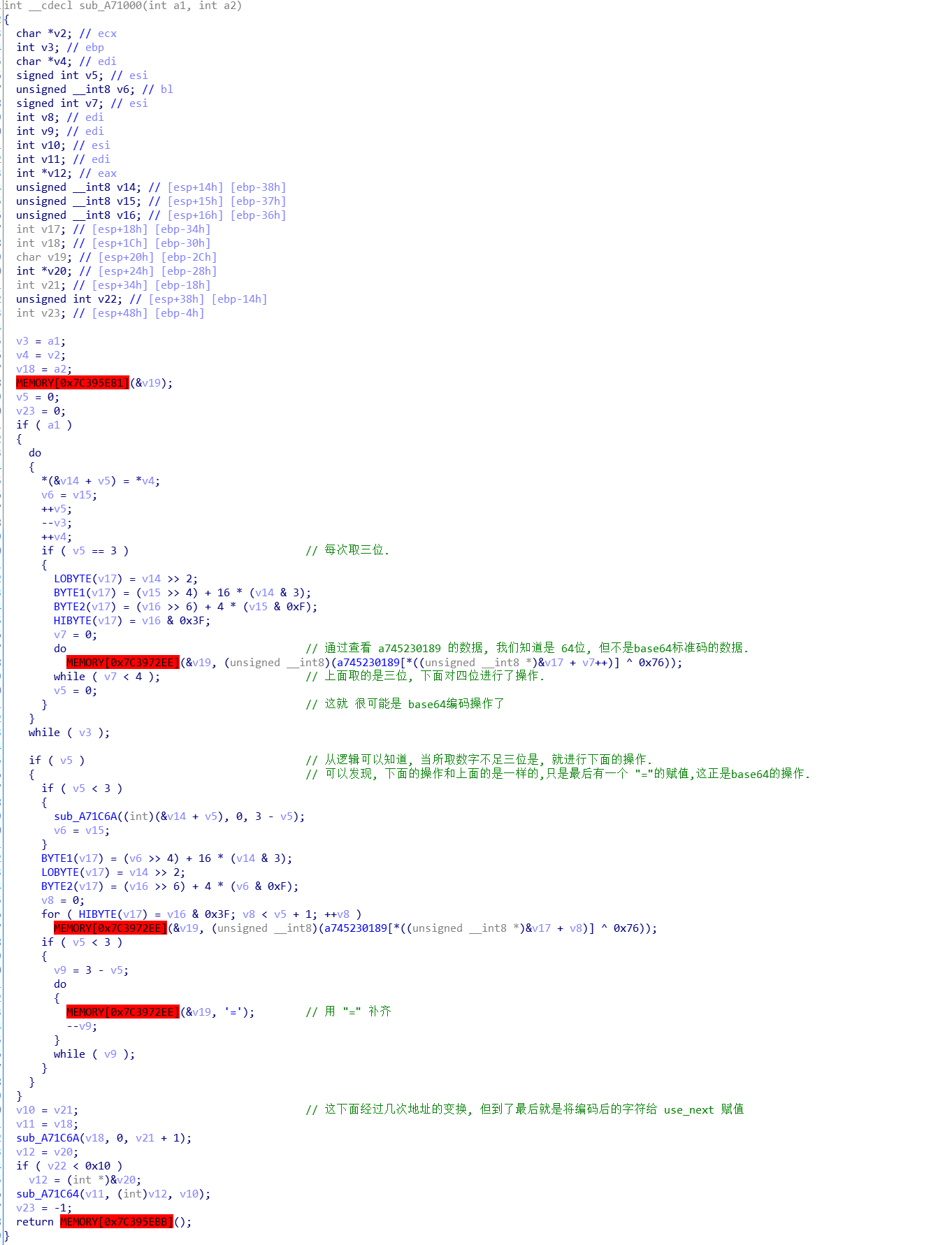
然后看关键的加密函数, 发现最下面还有一个函数 sub_A71000.
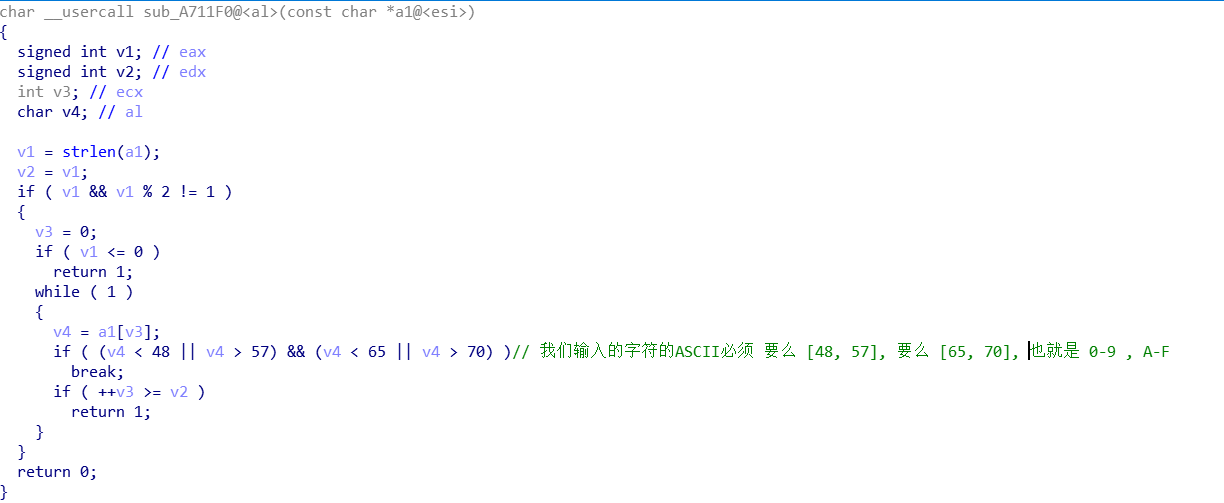
sub_A7100, 刚开始看这个函数觉得很麻烦, 但是从以前做的题来看, 并且这个函数有 >> 运算符. 可以往base编码考虑, 那就先看看有没有base编码的标志.
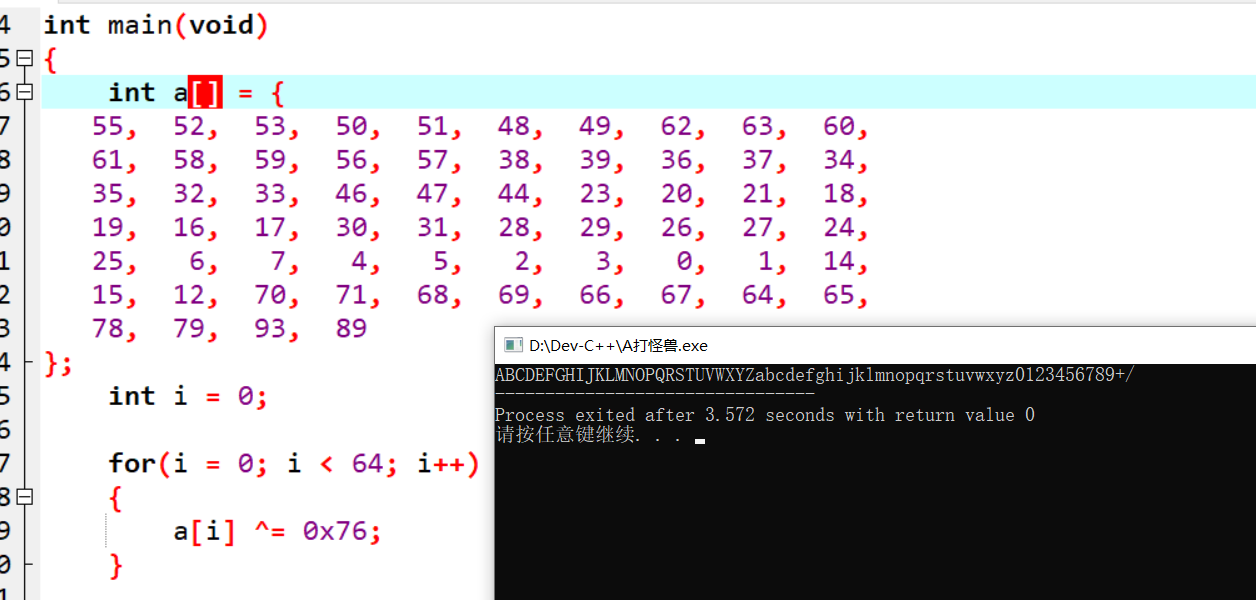
到了这里 , 可以知道, 程序只是标准码换了一下. 我们就用程序编码的数据和 0x76 异或运算得到 得到这里的base64 的码. 然后这个码去解码后面用来做比较的字符,得到第一次转换后的结果. 但是异或运算后, 我们发现这个码就是base64标准码.
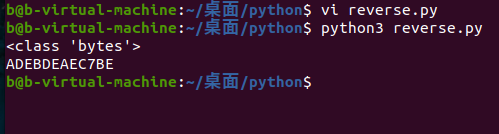
最后, 知道开始是把我们输入的字符进行数值转换的, 那么最后解码后我们也要还原一下. 懒得C语言自己写了, 用 python 的 hex(). 最后 flag就是 ADEBDEAEC7BE
1 2 3 4 import base64s = base64.b64decode('reverse+' ) print (type(s)) / 刚学python,查看一下是什么类型,因为用hex(), 发现 list, tuple都没有 hex().print (s.hex().upper())
总结: 1.题目有时候看起来代码很冗长, 但逻辑不难的, 细心分析一下. 要注意base家族的编码与解码. 2.正在学习python中, 每次写python脚本都有收获.
字符串前添加r , 表示后续的字符串原样输出, 不进行转义. 如 \\ 转义后为 \ 字符串前添加b, 后面字符串是bytes 类型 在 Python3 中,bytes 和 str 的互相转换方式是:str.encode(‘utf-8’) bytes.decode(‘utf-8’)
Windows_Reverse1 首先这道题与上面的一道是一起的, 做了上面的一道题, 觉得应该还是有壳的, 查一下是 upx.
载入OD还是使用堆栈平衡的原理脱壳, 发现同样是每次载入的地址不一样, 脱壳后还是不能运行, 还是要修复输入表, 但import rec又找不到我电脑的文件…….就先把题做了再来研究.
ida载入后十分简洁. 一个加密函数后进行判断. 看加密函数.
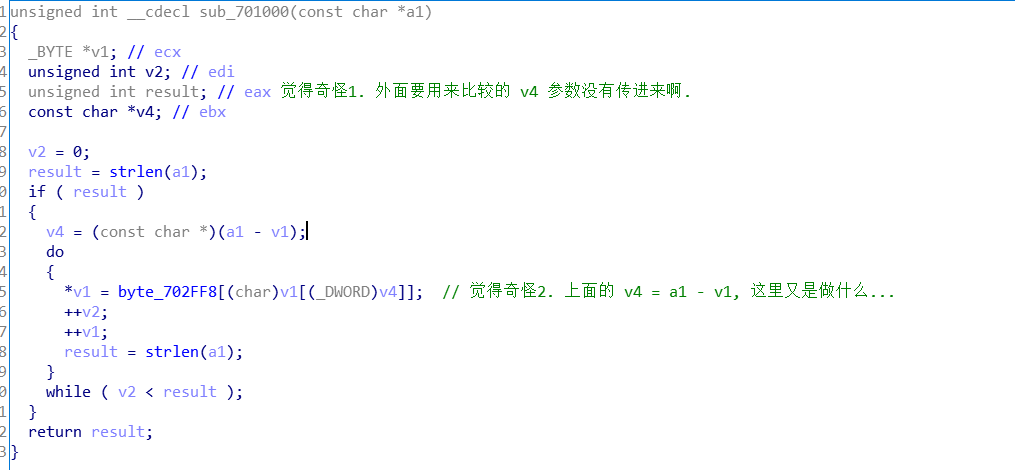
因为上面的 Reverse1 也是又同样的问题(不同的变量如何联系在一起的 ), 变量地址是相同的. 就先看看上面 v1的地址, 发现是 ecx 传来的 , 那再看看上一层函数的 ecx . 发现在调用这个加密函数之前有一个ecx赋值. 而要用来最后比较的 v4变量, 它的地址和传给ecx是一样的 . 那这里就是通过寄存器传递的参数.
上面的代码觉得奇怪, 怀疑是ida的原因, 把原程序到 OD 动态调试看一下加密函数. 清晰很多.
所以这个函数就是通过我们输入的ASCII为索引值来依次取出编码字符的数据, 最后DDCTF{reverseME} 进行比较.
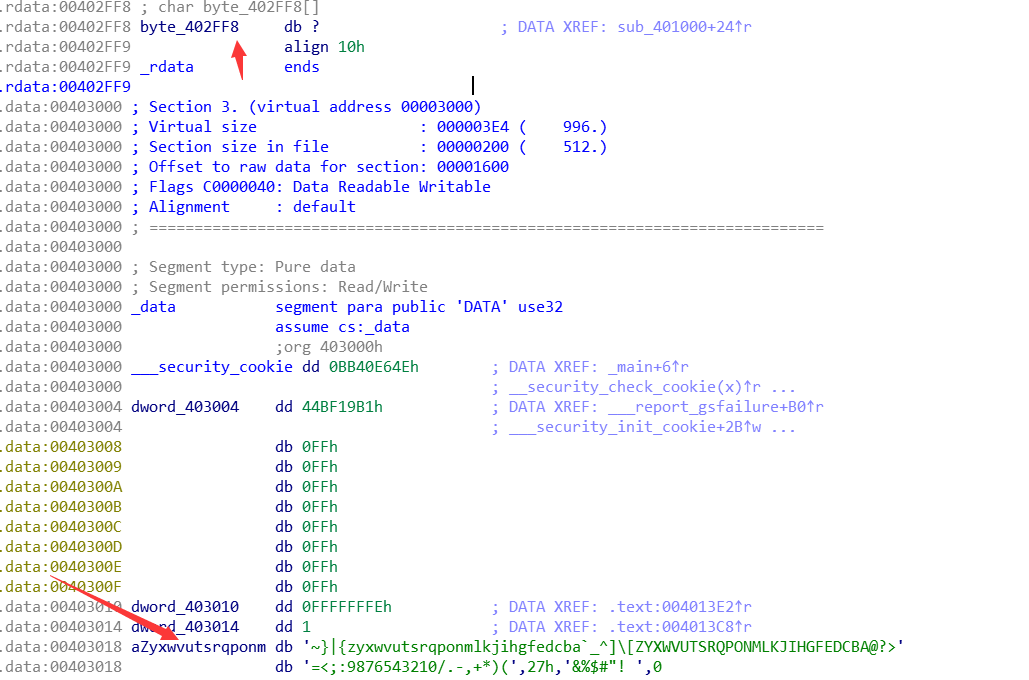
可以看到是从 0x402FF8 为首地址开始索引, 但是从ida中可以知道 可打印字符是从0x403018开始的.
最后,我遇到的很大的坑…..🤣, 字符串复制下来后, 我没有处理其中的 \ 的字符, 那么就被默认为转义字符了, 导致2个字符变成一个, 最后结果肯定错. 花了好多时间找这个错误, 还是没有在细节上注意😢. exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <stdio.h> #include <string.h> int main (void ) char a[] = "~}|{zyxwvutsrqponmlkjihgfedcba`_^]\\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/.-,+*)(',27h,'&%$#\"! " ; char b[] = "DDCTF{reverseME}" ; int i = 0 , j = 0 ; char flag[100 ] = {0 }; for (i = 0 ; i < strlen (b); i++) { for (j = 0 ; j < strlen (a); j++) { if (a[j] == b[i]) { flag[i] = j + 0x20 ; break ; } } } puts (flag); return 0 ; }
做完后,开始去了解 ASLR , 知道了开启ASLR的PE文件会多了一个.reloc节区, 且IMAGE_OPTIONAL_HEADER32结构中的DllCharacteristics多了一个属性. 如果一个程序开启了ASLR保护, 我们可以将这个DllCharacteristics的值从8140 改为8100 从而关闭ASLR.
总结: (1)一个程序中的参数可能会以寄存器的来传递 (2)字符串中注意 \ 字符, 要用 \\来表示 \ 字符. (3)程序的ASLR的开启标志及关闭方法.
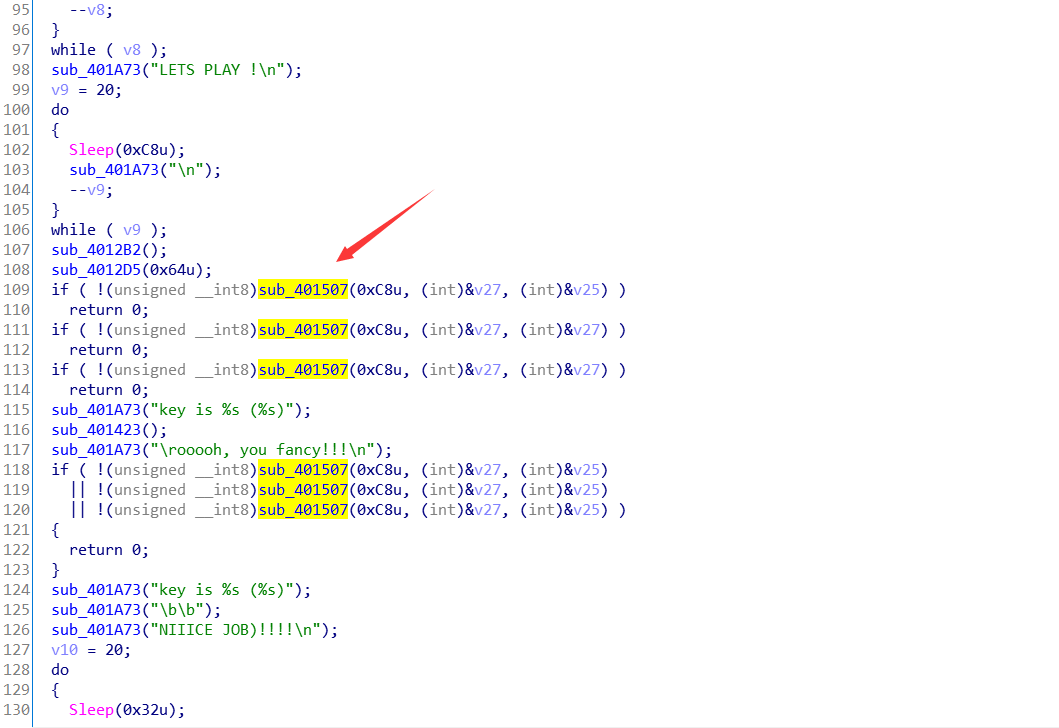
gametime 首先查壳, 发现无壳. 打开程序看一下. 果然是一个游戏, 简单的看了一下, 是让我们在规定时间输入屏幕上显示的字符.
ida打开, 看伪代码, 很冗长, 向下浏览一下可以看见好几个判断函数. 且都是一个函数, 程序肯定不应该是退出. 我们的目的就是让它的返回值为 非0
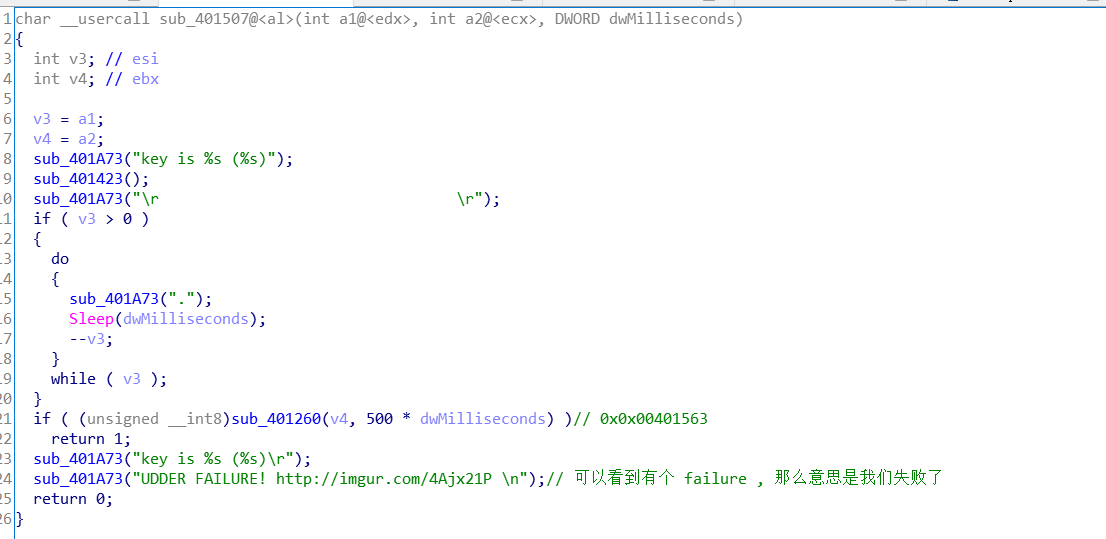
进入 sub_401507 看看. 发现还有个判断的地方, 我们的目的: 让它返回1 记录下地址. 0x00401563 .
此时程序下面还有类似的判断函数, 那么相同的方法, 先找到地址, 记录下来.
最后发现, 程序的核心判断函数就只有2个. 地址分别为: 0x00401563 , 0x004014DB
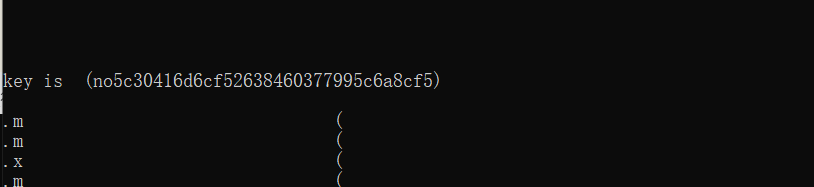
把程序载入OD. 跳到我们找到的地址, 发现地址对不上, 那程序是开启了 ASLR 的, 但是 RVA 是一样的, 简单的算一下就可以了. 另外一个地址, 相同的操作.
最后F9运行, 游戏进行一段时间, 出现flag.
总结: 简单的动态调试的应用, 注意地址是不是 image base.
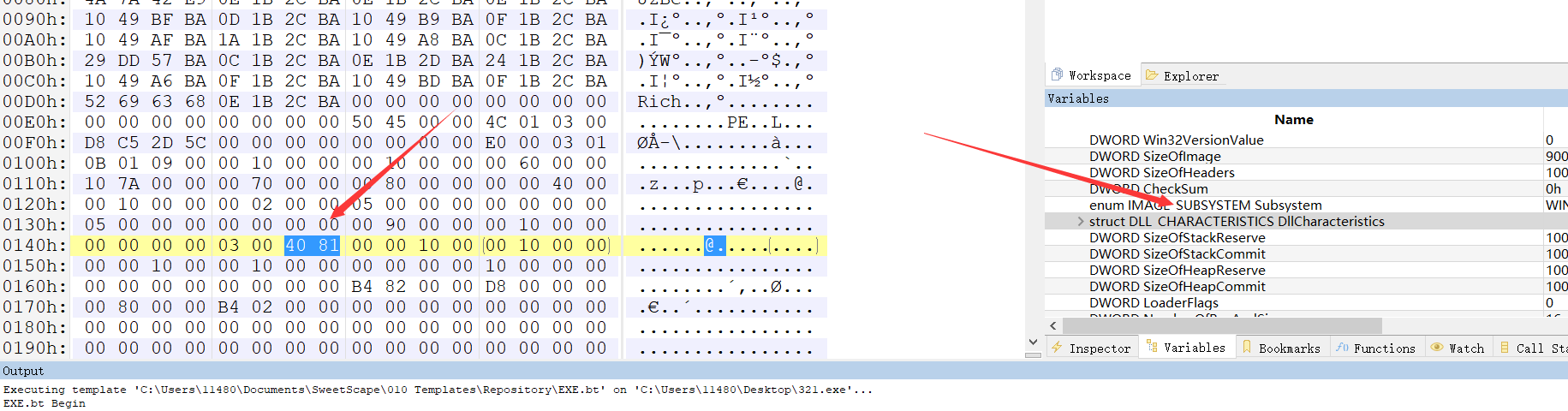
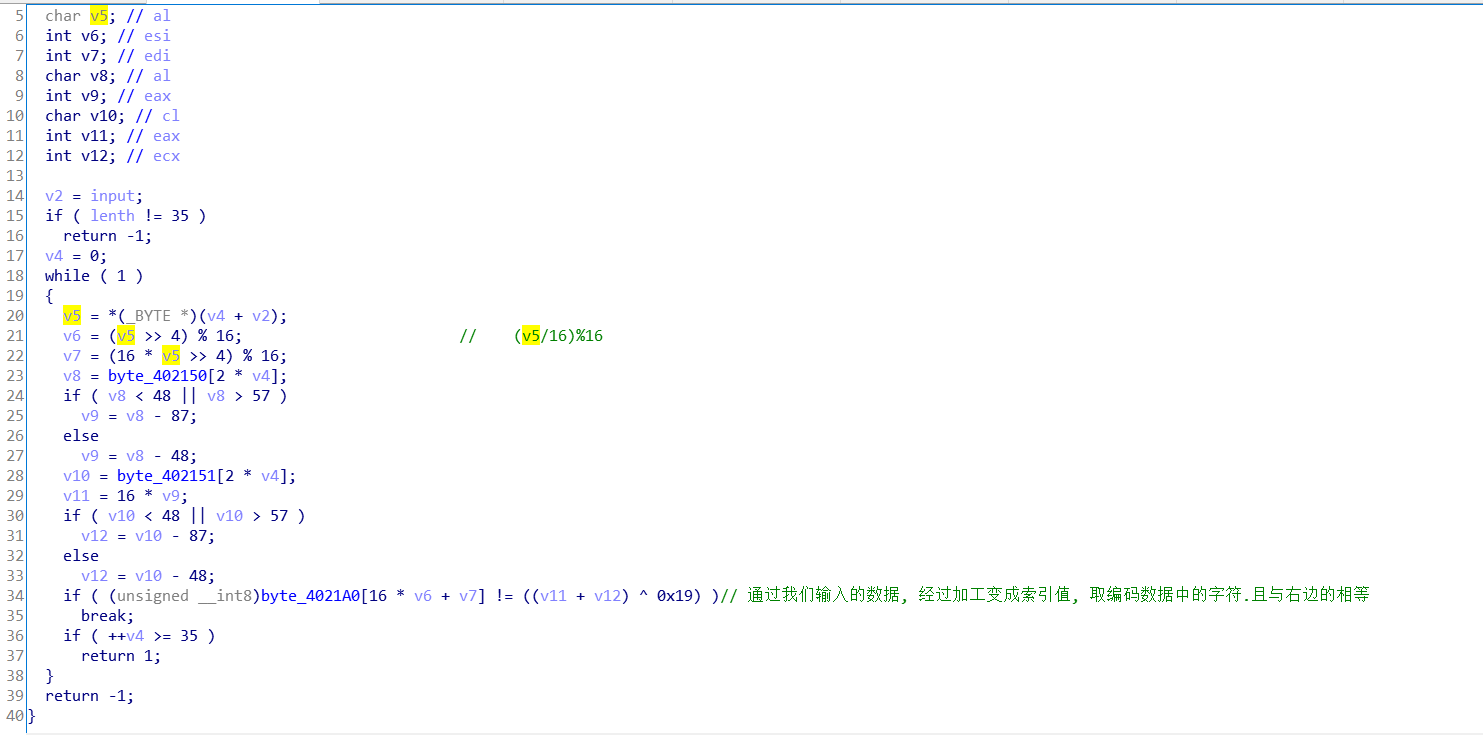
Replace 首先查壳, 发现是 upx. 载入OD, 准备脱壳, 但是发现 VA 不是默认加载的0x400000, 应该是开启了 ASLR. 转到010editor,找到 struct DLL_CHARACTERISTICS DllCharacteristics , 将8140改为8100.
接下来, 重新载入OD,使用堆栈平衡找到程序 EOP, 然后 dump.
脱壳后载入IDA, 程序逻辑简单, 首先限制长度 <= 37, 然后一个判断函数, 我们进入: 算法也不难.
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #include <stdio.h> int main (void ) char a[] = { 50 , 97 , 52 , 57 , 102 , 54 , 57 , 99 , 51 , 56 , 51 , 57 , 53 , 99 , 100 , 101 , 57 , 54 , 100 , 54 , 100 , 101 , 57 , 54 , 100 , 54 , 102 , 52 , 101 , 48 , 50 , 53 , 52 , 56 , 52 , 57 , 53 , 52 , 100 , 54 , 49 , 57 , 53 , 52 , 52 , 56 , 100 , 101 , 102 , 54 , 101 , 50 , 100 , 97 , 100 , 54 , 55 , 55 , 56 , 54 , 101 , 50 , 49 , 100 , 53 , 97 , 100 , 97 , 101 , 54 , 0 }; char b[] = { 97 , 52 , 57 , 102 , 54 , 57 , 99 , 51 , 56 , 51 , 57 , 53 , 99 , 100 , 101 , 57 , 54 , 100 , 54 , 100 , 101 , 57 , 54 , 100 , 54 , 102 , 52 , 101 , 48 , 50 , 53 , 52 , 56 , 52 , 57 , 53 , 52 , 100 , 54 , 49 , 57 , 53 , 52 , 52 , 56 , 100 , 101 , 102 , 54 , 101 , 50 , 100 , 97 , 100 , 54 , 55 , 55 , 56 , 54 , 101 , 50 , 49 , 100 , 53 , 97 , 100 , 97 , 101 , 54 , 0 }; int i = 0 , j = 0 ; char flag[100 ] = {0 }; unsigned char c[] = { 99 , 124 , 119 , 123 , 242 , 107 , 111 , 197 , 48 , 1 , 103 , 43 , 254 , 215 , 171 , 118 , 202 , 130 , 201 , 125 , 250 , 89 , 71 , 240 , 173 , 212 , 162 , 175 , 156 , 164 , 114 , 192 , 183 , 253 , 147 , 38 , 54 , 63 , 247 , 204 , 52 , 165 , 229 , 241 , 113 , 216 , 49 , 21 , 4 , 199 , 35 , 195 , 24 , 150 , 5 , 154 , 7 , 18 , 128 , 226 , 235 , 39 , 178 , 117 , 9 , 131 , 44 , 26 , 27 , 110 , 90 , 160 , 82 , 59 , 214 , 179 , 41 , 227 , 47 , 132 , 83 , 209 , 0 , 237 , 32 , 252 , 177 , 91 , 106 , 203 , 190 , 57 , 74 , 76 , 88 , 207 , 208 , 239 , 170 , 251 , 67 , 77 , 51 , 133 , 69 , 249 , 2 , 127 , 80 , 60 , 159 , 168 , 81 , 163 , 64 , 143 , 146 , 157 , 56 , 245 , 188 , 182 , 218 , 33 , 16 , 255 , 243 , 210 , 205 , 12 , 19 , 236 , 95 , 151 , 68 , 23 , 196 , 167 , 126 , 61 , 100 , 93 , 25 , 115 , 96 , 129 , 79 , 220 , 34 , 42 , 144 , 136 , 70 , 238 , 184 , 20 , 222 , 94 , 11 , 219 , 224 , 50 , 58 , 10 , 73 , 6 , 36 , 92 , 194 , 211 , 172 , 98 , 145 , 149 , 228 , 121 , 231 , 200 , 55 , 109 , 141 , 213 , 78 , 169 , 108 , 86 , 244 , 234 , 101 , 122 , 174 , 8 , 186 , 120 , 37 , 46 , 28 , 166 , 180 , 198 , 232 , 221 , 116 , 31 , 75 , 189 , 139 , 138 , 112 , 62 , 181 , 102 , 72 , 3 , 246 , 14 , 97 , 53 , 87 , 185 , 134 , 193 , 29 , 158 , 225 , 248 , 152 , 17 , 105 , 217 , 142 , 148 , 155 , 30 , 135 , 233 , 206 , 85 , 40 , 223 , 140 , 161 , 137 , 13 , 191 , 230 , 66 , 104 , 65 , 153 , 45 , 15 , 176 , 84 , 187 , 22 , 72 , 0 , 0 , 0 , 0 }; for (i = 0 ; i < 35 ; i++) { int temp = 0 , temp1 = 0 , q = 0 , w = 0 ; for (j = 0 ; j < 127 ; j++) { temp = (j >> 4 ) % 16 ; temp1 = (16 *j >> 4 ) % 16 ; q = a[2 *i]; if (q < 48 || q > 57 ) q = q-87 ; else q = q-48 ; q = q*16 ; w = b[2 *i]; if (w < 48 || w > 57 ) w = w-87 ; else w = w-48 ; if (c[16 *temp + temp1] == ((w+q) ^ 0x19 )) { flag[i] = j; break ; } } } puts (flag); return 0 ; }
总结: >> 运算符移动n位就相当于除以2^n. 且 % 的优先级大于 >>
notsequence 自己算法太菜了, 这道题的2个函数始终没看懂… 看了writeup, 杨辉三角形!
看了writeup, 自己慢慢的分析了下. 首先, check1函数.
然后是check2.
经过这2个函数判断, 就能知道是否是杨辉三角形了. 把前20行的数据经过md5加密就是flag.
最后, 题自己虽然每做出来, 倒是通过这个题重新认识了杨辉三角形. 写了C语言和python的版本. 也是想打印出来看看, 且自己刚接触python, 代码乱而长.
python3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def createL (l) : L = [1 ] for x in range(1 , len(l)): L.append(l[x] + l[x-1 ]) L.append(1 ) return L def printL (L, W) : s = "" for x in L: s += str(x) + " " print(s.center(W)) def str_ (s, L) : for x in L: s += str(x) return s import hashlibL = [1 ] s = "" row = int(input("请输入行数: " )) width =row* 6 for x in range(row): printL(L, width) s = str_(s, L) L = createL(L) print(s) m = hashlib.md5(s.encode()).hexdigest() print("md5加密后:%s" % m)
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <stdio.h> #include <stdlib.h> #include <string.h> int *creat (int *L, int lenth) int i = 0 ; int *p = (int *)malloc (sizeof (int )*(lenth+1 )); p[0 ] = 1 ; for (i = 1 ; i < lenth; i++) p[i] = L[i-1 ] + L[i]; p[lenth] = 1 ; return p; } void print (int *L, int blank_l, int lenth) int i = 0 ; for (i = 0 ; i < blank_l; i++) printf (" " ); for (i = 0 ; i < lenth; i++) printf ("%4d" , L[i]); putchar (10 ); } char *translate (int *L, int lenth) int i = 0 ; char *p = (char *)malloc (sizeof (char )*100 ), temp[100 ] = {0 }; memset (p, 0 , sizeof (char )); for (i = 0 ; i < lenth; i++) { sprintf (temp, "%d" , L[i]); strcat (p, temp); } return p; } int main (void ) int n = 0 , i = 0 , *p = NULL ; char a[1000 ] = {0 }; printf ("请输入行数: " ); scanf ("%d" , &n); for (i = 0 ; i < n; i++) { p = creat(p, i); print (p, n-i, i+1 ); strcat (a, (char *)translate(p, i+1 )); } printf ("\n所有数值组成的字符串为: %s" , a); return 0 ; }
总结: 在看不懂代码的时候, 应该把能写出来的值都列举出来, 观察一下规律.
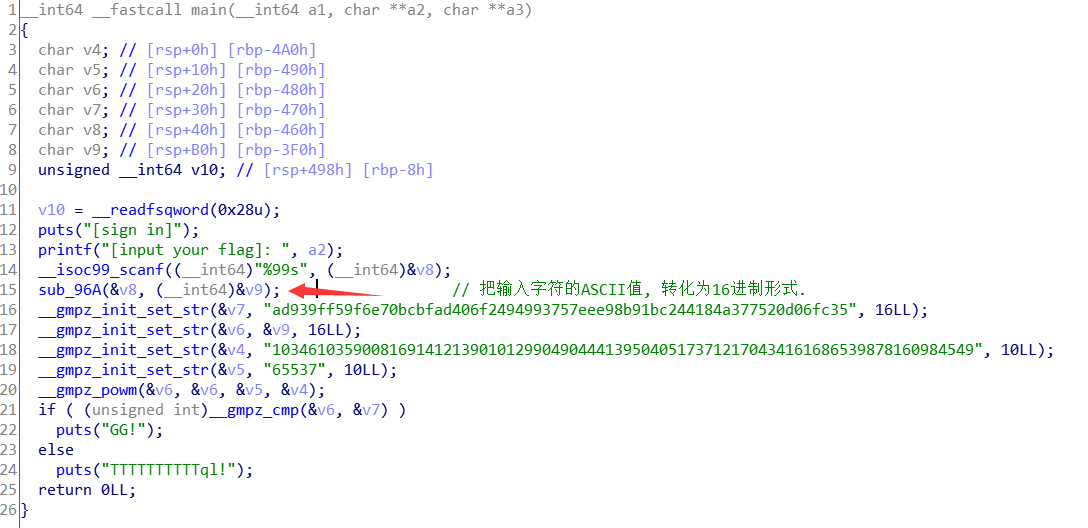
SignIn 这道题更像是是crypto的题, 初次了解了下Rsa.
程序下载下来, 有一系列不认识的函数, 大概知道用法, 还是先取查了查.
GMP(The GNU Multiple Precision Arithmetic Library)又叫GNU多精度算术库,是一个提供了很多操作高精度的大整数,浮点数的运算的算术库,几乎没有什么精度方面的限制,功能丰富. 几个常用的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 添加头文件:#include <gmp.h> cmd编译命令:gcc myprogram.c -lgmp -lm -o myprogram 声明一个gmp的整数rop :mpz_t rop; 把字符串初始化为gmp大整数:int mpz_init_set_str (mpz_t rop, char *str, int base) 释放空间:void mpz_clear (mpz_t rop) 加法:void mpz_add (mpz_t rop, mpz_t op1, mpz_t op2) 减法:void mpz_sub (mpz_t rop, mpz_t op1, mpz_t op2) 乘法:void mpz_mul (mpz_t rop, mpz_t op1, mpz_t op2) 除法:void mpz_cdiv_q (mpz_t q, mpz_t n, mpz_t d) 幂运算:void mpz_pow_ui (mpz_t rop, mpz_t base, unsigned long int exp ) void mpz_powm (mpz_t rop, const mpz_t base, const mpz_t exp, const mpz_t mod) 作用: Set rop to base^exp mod mod. 这是这道题中用到的. 也是rsa加密解密常用的. 开方:void mpz_sqrt (mpz_t rop, mpz_t op)
整个流程, 显然是rsa加密.
步骤 说明 描述 备注 1 找出质数 P 、Q - 2 计算公共模数 N = P * Q - 3 欧拉函数 φ(N) = (P-1)(Q-1) - 4 计算公钥E 1 < E < φ(N) E的取值必须是整数 E 和 φ(N) 必须是互质数 5 计算私钥D E * D % φ(N) = 1 - 6 加密 C = M ^E mod N C:密文 M:明文 7 解密 M =C ^D mod N C:密文 M:明文
但是之前有一个sub_96A函数.(最上面的箭头所示), 现在进入这个函数看看. 这里是从字符的ASCII转化为16进制, (最上面的 Windows_Reverse2有从 16进制转化为字符的算法, 都挺简洁的)
整个程序就是将我们输入的字符, 先转化为16进制数值字符, 再变成一个大数作为明文. 经过 C = M ^E mod N , 加密后和编码的密文进行对比. 首先这里的 E = v5 = 65537. M是明文. N = v4 = 103461035900816914121390101299049044413950405173712170434161686539878160984549. 根据解密过程, 我们先把 N 分解成 p q , 可以去在线分解.
然后使用 python的gmpy2库先求逆元得到D . 最后用 M =C ^D mod N 解密并从16进制转化为字符. 这个gmpy2的库的安装还费了些时间..🤣 exp:
1 2 3 4 5 6 7 8 9 10 11 import gmpy2p = 282164587459512124844245113950593348271 q = 366669102002966856876605669837014229419 N = 103461035900816914121390101299049044413950405173712170434161686539878160984549 c = 0xad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35 e = 65537 d = gmpy2.invert(e, (p-1 )*(q-1 )) m = gmpy2.powmod(c, d, p*q) print(bytes.fromhex(hex(m)[2 :])
总结: (1)对rsa有了初步的了解, 学会了简单的加密解密方法. (2)GMP算数库的认识. (3)字符的ASCII转16进制的简洁算法.
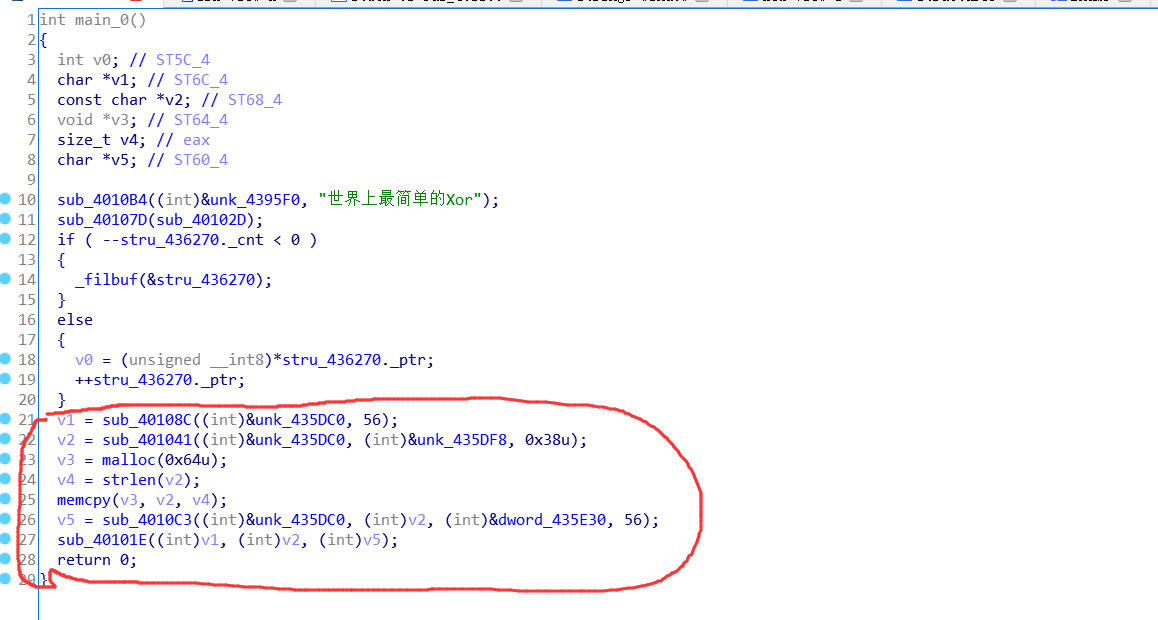
BabyXor 首先, 明明可以直接OD动态调试, 很快得到flag. 但是我用ida把题做完, 才一下子想起.🤣
发现有壳, 载入OD使用堆栈平衡脱壳. 载入ida, 发现main函数里有很多函数, 上下分析了下, 发现都是干扰的函数.
确定目标, 就是通过这几个函数从编码的数据中取出字符经过一些简单的异或运算, 存放再一个内存空间. 但是与我们输入数据没有关系. (这时候, 就可以直接取OD动态调试直接得到flag的, 唉, 我算出来才想起)
一个疑问的地方
然后看了看汇编代码. 还是不清楚.
进去OD调试看看.发现代码又是一个样. 不过这下就清楚了. 先取地址的值. 记住这点
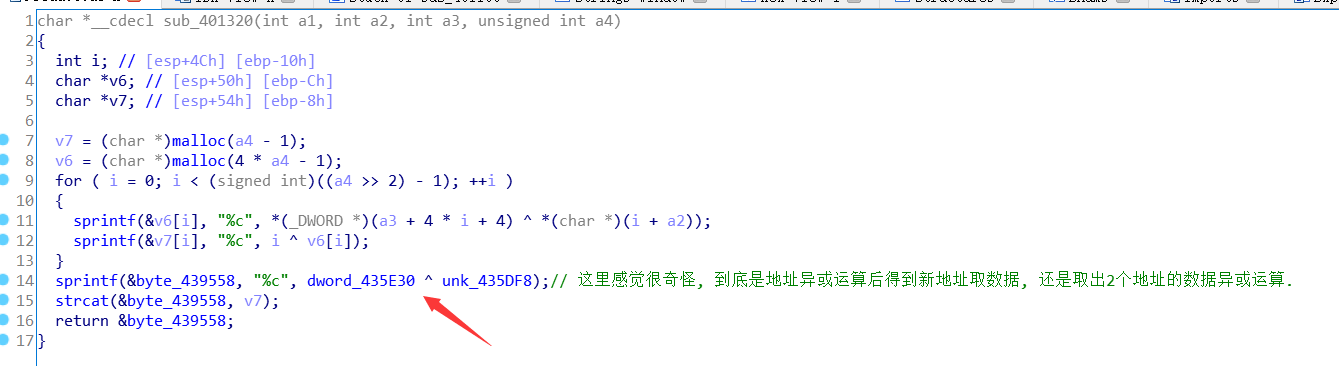
解题脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <stdio.h> #include <string.h> int main (void ) union { unsigned char ida_chars[56 ]; int a[14 ]; }A = { 102 , 0 , 0 , 0 , 109 , 0 , 0 , 0 , 99 , 0 , 0 , 0 , 100 , 0 , 0 , 0 , 127 , 0 , 0 , 0 , 55 , 0 , 0 , 0 , 53 , 0 , 0 , 0 , 48 , 0 , 0 , 0 , 48 , 0 , 0 , 0 , 107 , 0 , 0 , 0 , 58 , 0 , 0 , 0 , 60 , 0 , 0 , 0 , 59 , 0 , 0 , 0 , 32 , 0 , 0 , 0 }; union { unsigned char ida[56 ]; int a[14 ]; } B = { 55 , 0 , 0 , 0 , 111 , 0 , 0 , 0 , 56 , 0 , 0 , 0 , 98 , 0 , 0 , 0 , 54 , 0 , 0 , 0 , 124 , 0 , 0 , 0 , 55 , 0 , 0 , 0 , 51 , 0 , 0 , 0 , 52 , 0 , 0 , 0 , 118 , 0 , 0 , 0 , 51 , 0 , 0 , 0 , 98 , 0 , 0 , 0 , 100 , 0 , 0 , 0 , 122 , 0 , 0 , 0 }; union { unsigned char ida_[56 ]; int a[14 ]; }C = { 26 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 81 , 0 , 0 , 0 , 5 , 0 , 0 , 0 , 17 , 0 , 0 , 0 , 84 , 0 , 0 , 0 , 86 , 0 , 0 , 0 , 85 , 0 , 0 , 0 , 89 , 0 , 0 , 0 , 29 , 0 , 0 , 0 , 9 , 0 , 0 , 0 , 93 , 0 , 0 , 0 , 18 , 0 , 0 , 0 }; char f1[14 ] = {0 }, f2[14 ] = {0 }, f3[14 ] = {0 }, ftemp[14 ] = {0 }, temp = 0 ; char flag[100 ] = {0 }; int i = 0 ; for (i = 0 ; i < 14 ; i++) { f1[i] = A.a[i] ^ i; } f2[0 ] = B.a[0 ]; for (i = 1 ; i < 14 ; i++) { f2[i] = A.a[i] ^ B.a[i] ^ A.a[i-1 ]; } for (i = 0 ; i < 13 ; i++) { temp = C.a[i+1 ] ^ f2[i]; ftemp[i] = temp ^ i; } f3[0 ] = 0x2D ; strcat (f3, ftemp); strcat (flag, f1); strcat (flag, f2); strcat (flag, f3); puts (flag); return 0 ; }
下面说一步到位.找到最后一个函数最后赋值代码的地址. 复制下来
进去OD, 跳到这个地址下断点, 运行起来. 看数据窗口.
总结: (1)注意这种flag和输入字符无关的的题. (2)这里 ida中的内存取值与OD中的差异.
easy_Maze 这道题对新手还是很好.
由题目我们能知道是关于迷宫的题. 下载下来是elf文件, 查壳后无壳, 在linux下运行看看大概流程.
载入IDA, 先分析了接受我们输入的字符的函数. 知道在外面一层的主函数是先生成一个每行7个元素的数组. 然后通过我们输入的字符按控制在矩阵迷宫中走向, 最后按照规定的到达一个目的地.
接下来返回外侧的主函数, 就是生成矩阵的了. 通过上面的49个元素知道且下面函数的参数7, 知道规模 7*7.
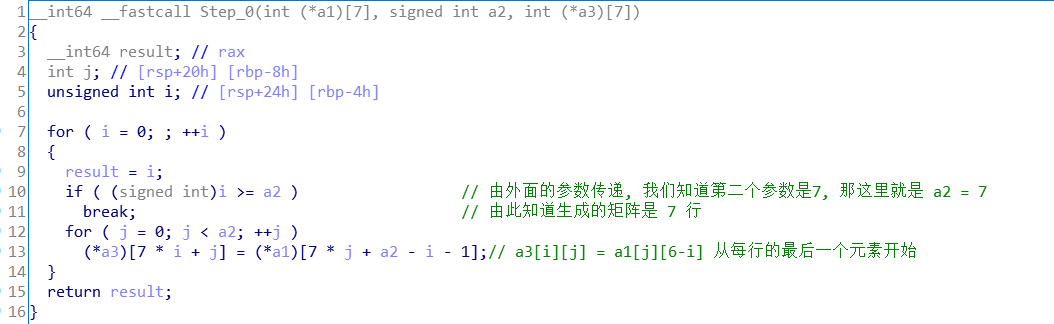
进入Step_0 看看. 就是简单的把上面49个元素赋值给 v7 数组, 也印证了数组是7*7
接下来 Step_1 , 看起来是很简洁, 但里面的 getA 与 getAstart 函数 算法太冗长了.
这个时候, 开始我就把生成矩阵的所有函数及数据都复制到VC 编译器中, 再根据栈的特点改下数据的顺序(数据存放是从下往上, 那么我们取数据时地址每次减1而不是加一 ), 然后运行打印出矩阵. 问题是运行后什么也没有打印, 调试发现一个函数中的内存空间和另外一个冲突, 相互覆盖值. 这个函数太多,关联性大, 改起来也麻烦.
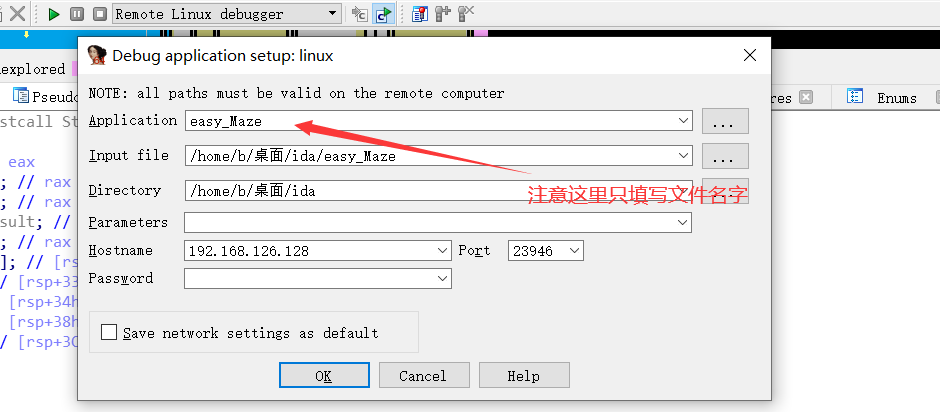
然后转向GDB调试, 但是不熟练. 又转向ida动态调试. 首先在 IDA 的安装目录/dbgsrc/找到 linux_server 和 linux_server64 拷贝到 linux ,在linux中运行 linux_server64 , 然后在Debugger的 process options 如下图格式配置. 然后F9开始.
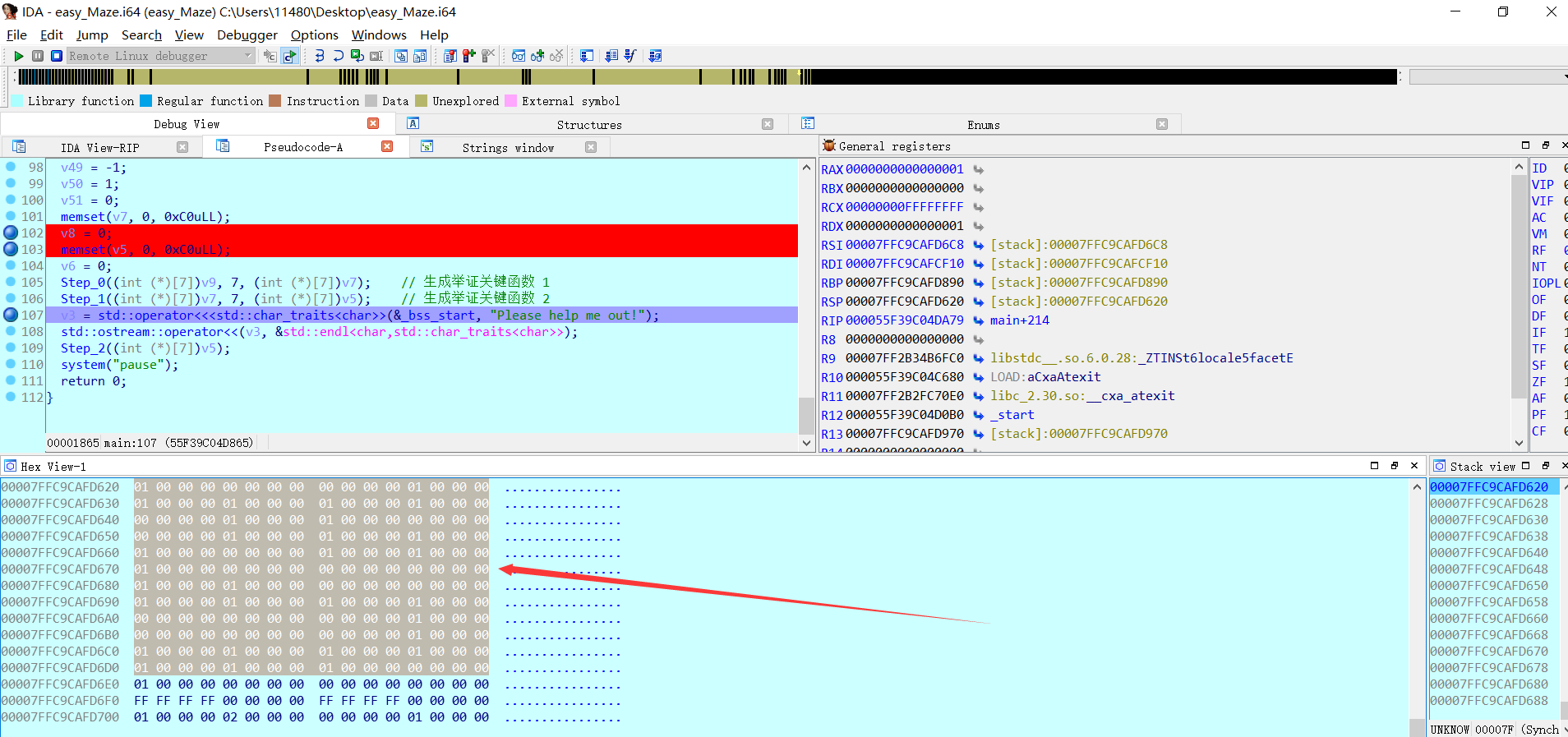
先下断点, 找到储存矩阵的空间的地址, 把这个地址转到数据窗口跟随, 然后运行到生成矩阵的下面一个函数(也就是(Step_1 下面). 在数据窗口出现我们的数据(int型), 由于是49个元素, 49*4/16 = 12 …4 ,那就是12行加4个数据, shift+E 提取出C语言格式的数据.
数据得到后, 用C语言打印出来好观察, 注意每个数据4个字节(小端).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <stdio.h> int main (void ) union { unsigned char ida_chars[196 ]; int a[49 ]; }A = { 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 }; int i = 0 , j = 0 ; int (*p)[7 ] = (int (*)[7 ])A.a; for (i = 0 ; i < 7 ; i++) { for (j = 0 ; j < 7 ; j++) { printf ("%d " , p[i][j]); } putchar (10 ); } return 0 ; }
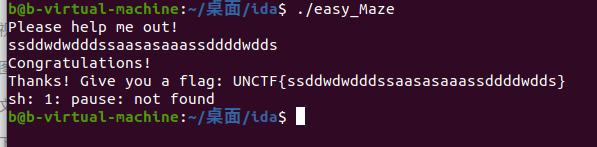
根据我们打游戏的熟悉 aswd ,朝着1走到最后. ssddwdwdddsssaasasaaassddddwdds 最后在linux下输入.
总结: 更加熟悉了linux动态调试的运用, 加深了数组指针的理解.
simple-check-100 题目本来很简单, 但是有坑啊…
首先, 题目下载下来, 有三个版本. 下意识的选择了熟悉的.exe来分析.
查壳无壳, 用ida打开. 第一直觉就是这个最后的flag与我们输入字符没关系, 直接OD动态调试跳过判断条件就好了.
还是先细看一下栈空间, 虽然还是和我们输入的字符没有关系. 但是有问题啊,要用的地址交叉了. 想着万一题就是这样呢, 先取OD试一下. 不出所料, 乱码😢
开始仔细分析下这个题的栈空间, 在OD反复调试, 发现我们输入字符的空间只有19个字节啊, 为什么我们输入的字符栈空间在OD中调试有19+32 = 51字节空间.
看了半天不知道为什么, 后面才看见程序下面有 v3 = alloca(32); 百度了一下, 这个是再栈上申请空间的函数. 正好是多出来的32.
经过反复调试, 这个题怎么也和我们输入的字符没关系啊, 程序每次过了判断条件, 算的都一样. 真的奇怪了.
最后没办法了,想不通. 就最后再把文件中这个程序的linux版本载入ida看看, 嗯….这个版本的栈空间就没有交叉. v7一直到v34, 没有像PE文件那个版本在中间多一个指针.
在linux下动态调试.
😂什么鬼题. PE文件版本居然是有问题的!!!
总结: 文件有多个版本的时候, 注意!!! 张见识了. 虽然多花了时间在PE上耗, 但是对栈更清楚了.
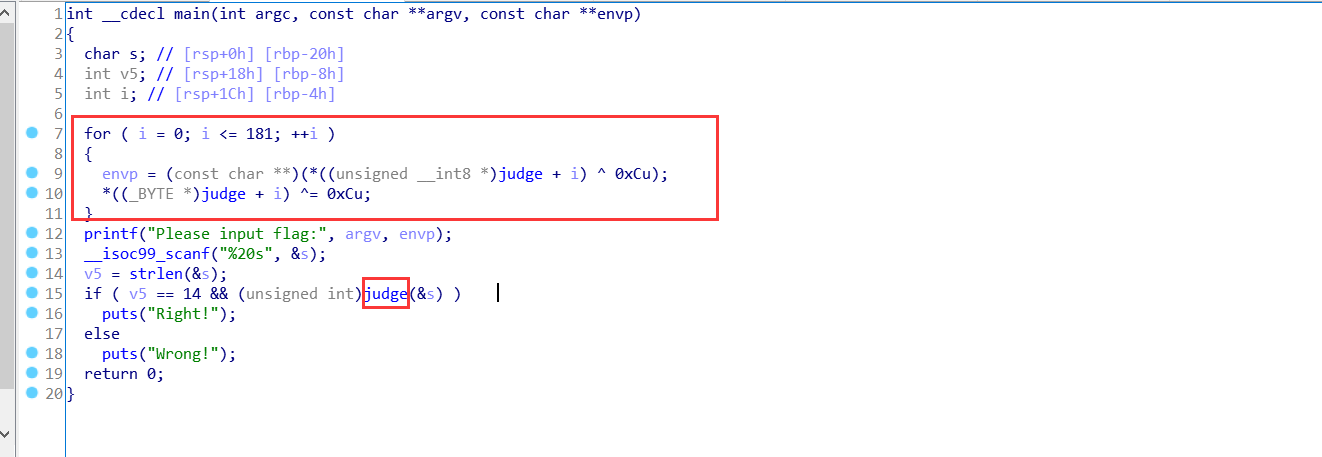
zorropub 查壳查位数后载入ida, 整体思路如下.
那其实我们是不用管这个 MD5 加密的 , 也不会这个解密. 直接爆破找到 i 值从而得到随机数种子.
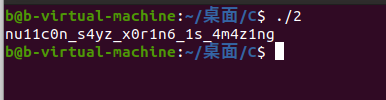
那问题来了, 爆破找了一个 i 值是1023, 就在linux写了exp(不能在window下, 因为生成随机数不同 ). 但得到的数据都是乱码的, 我还是一直以为问题出现在 LOBYTE(取最低字节位) 因为第一次接触.
最后才想起那个 i 的值, 它可能不是唯一的. 开始写exp, 取大范围的数据爆破, 果然对了……
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <stdio.h> #include <stdlib.h> void func (int a, int *c) int b = 0 , f = 0 ; char flag[100 ] = {0 }; srand(a); for (int i = 0 ; i <= 29 ; i++) { b = rand()%1000 ; flag[i] = b^c[4 *i]; if (flag[i] > 126 || flag[i] < 32 ) f = 1 ; } if (!f) puts (flag); } int main () int i = 0 , b = 0 , j = 0 , cnt = 0 ; int a[1000 ] = { 200 , 3 , 0 , 0 , 50 , 0 , 0 , 0 , 206 , 2 , 0 , 0 , 2 , 3 , 0 , 0 , 127 , 0 , 0 , 0 , 184 , 1 , 0 , 0 , 126 , 3 , 0 , 0 , 136 , 1 , 0 , 0 , 73 , 3 , 0 , 0 , 127 , 2 , 0 , 0 , 94 , 0 , 0 , 0 , 52 , 2 , 0 , 0 , 84 , 3 , 0 , 0 , 163 , 1 , 0 , 0 , 150 , 0 , 0 , 0 , 64 , 3 , 0 , 0 , 40 , 1 , 0 , 0 , 252 , 2 , 0 , 0 , 0 , 3 , 0 , 0 , 142 , 2 , 0 , 0 , 38 , 1 , 0 , 0 , 27 , 0 , 0 , 0 , 42 , 3 , 0 , 0 , 245 , 2 , 0 , 0 , 95 , 1 , 0 , 0 , 104 , 3 , 0 , 0 , 235 , 1 , 0 , 0 , 121 , 0 , 0 , 0 , 29 , 1 , 0 , 0 , 78 , 2 , 0 , 0 }; char flag[100 ] = {0 }; for (i = 0 ; i < 100000 ; i++) { j = i; while (j) { cnt++; j &= j-1 ; if (cnt > 10 ) break ; } if (cnt == 10 ) func(i, a); cnt = 0 ; } return 0 ; }
然后做完, 还是去看看大佬的writeup. 想看看那个md5怎解密, 但是没有. 却发现好多都是用的pwntools工具来爆破的, 自己也去试了下, 确实简单很多.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import *a = [] for i in range(16 , 0xffff ): cnt = 0 j = i while (j): cnt += 1 j &= j-1 if cnt == 10 : a.append(i) for i in a: p = process("./11" ) p.recv() p.sendline('1' ) p.sendline(str(i)) ans = p.recv() if "NULL" in text: print (text) break p.close()
总结: (1)既然是爆破就要注意有多种情况 (2) LOBYTE 是ida的宏定义, 取最低字节位. (3)更加熟悉pwntools工具的使用.
BABYRE 题目不难, 但是第一次遇到这样的题.
64位elf文件, ida打开后, 和以往的文件不一样, 开始有一段循环计算赋值的操作,但是又是看不到到底是赋值给了谁.
那就动态调试跟来看看, 到了判断条件的时候. 明白了就是类似加壳的程序打开会先进行解压生成代码. 这里开始那一段循环作用, 就改变我们代码的.
跟进判断函数, 算法很简单,直接读汇编, 就是一个异或操作然后对比.
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> int main (void ) int a[] = {0x66 , 0x6D , 0x63 , 0x64 , 0x7F , 0x6B , 0x37 , 0x64 , 0x3B , 0x56 , 0x60 , 0x3B , 0x6E , 0x70 }; int i = 0 ; char flag[100 ] = {0 }; for (i = 0 ; i <= 13 ; i++) { flag[i] = a[i] ^ i; } puts (flag); return 0 ; }
总结: 算是长见识吧.
攻防世界刷题记录(4)。
asong 0x1分析 下载下来三个文件。
依次看了下, 一个64位elf文件无壳, 2个文本文件. 打开文本文件后,没有头绪. 将elf文件载入ida。
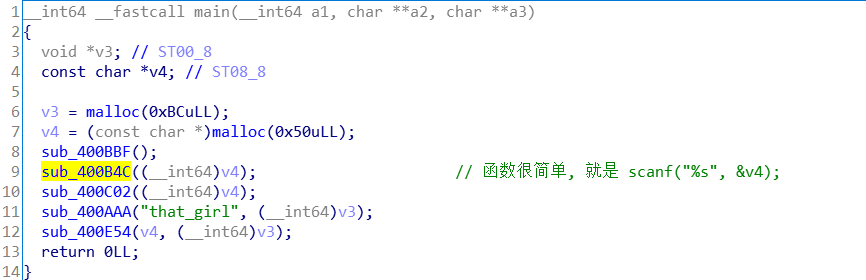
整个流程开始看不清楚做什么, 多看几次明白了. 先输入字符串, 打开一个that_girl文件读信息, 最后向out文件写信息. 但这怎么和flag联系起来呢. 其实那个out文件里的就是密文, 我们找到逆向算法, 通过密文求出明文(即我们的输入, 也是flag)
下面具体分析每个函数. 第一函数: sub_400B4C 由于很简单, 直接给出函数功能.
sub_400B4C : 先判断, 再取 { } 之间的内容.
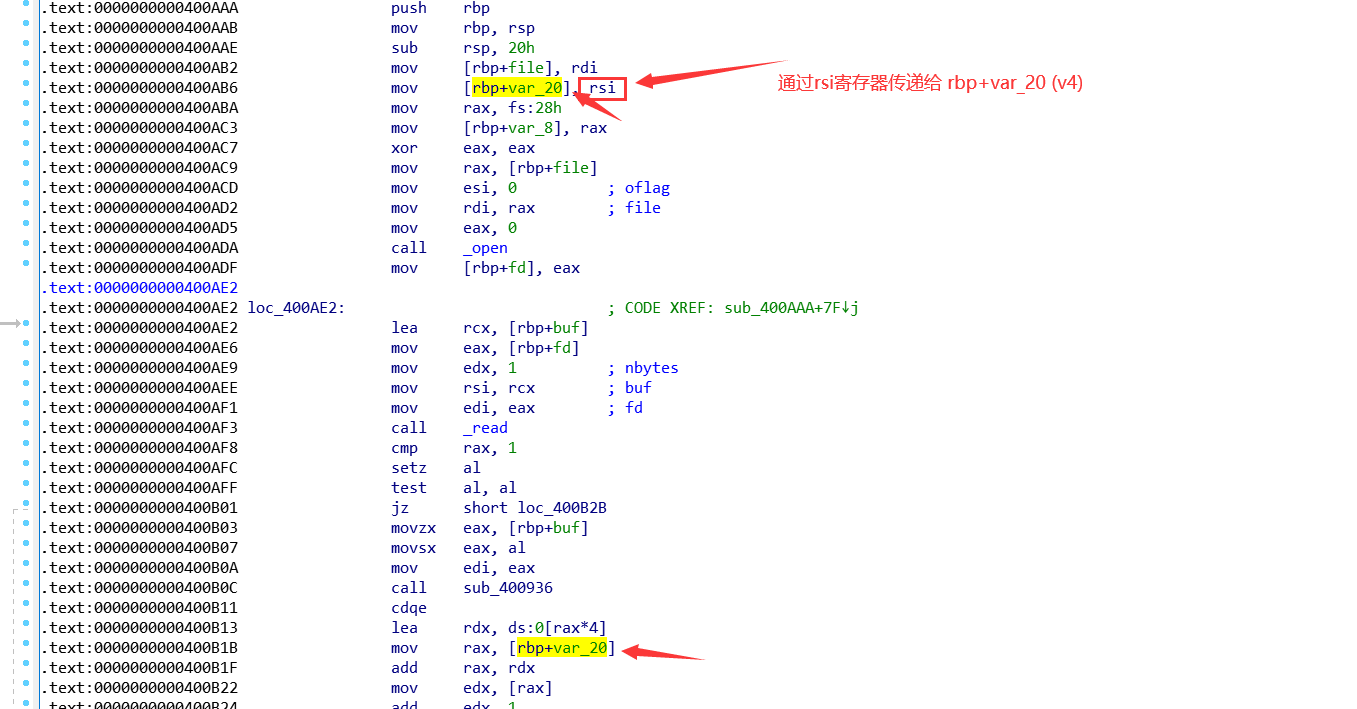
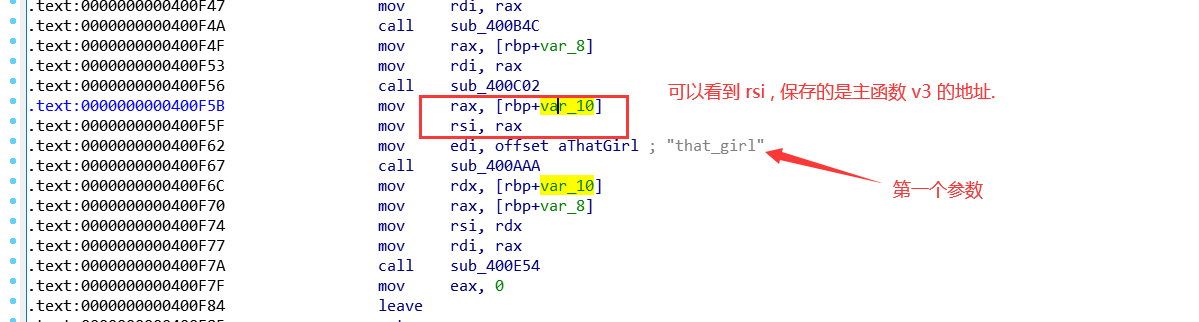
下面下一个函数, 疑问:v4哪里来的及 ++*(_DWORD *)(4LL * v2 + v4);语句的作用
sub_400936(&buf) :
第一次遇到, 没有经验, 后来才想到通过汇编的查看, v4即是我们传了参数 a2(也就是主函数的v3), 这是通过寄存器传递. 64位与32位程序的区别. 但该语句功能还不是很清楚.
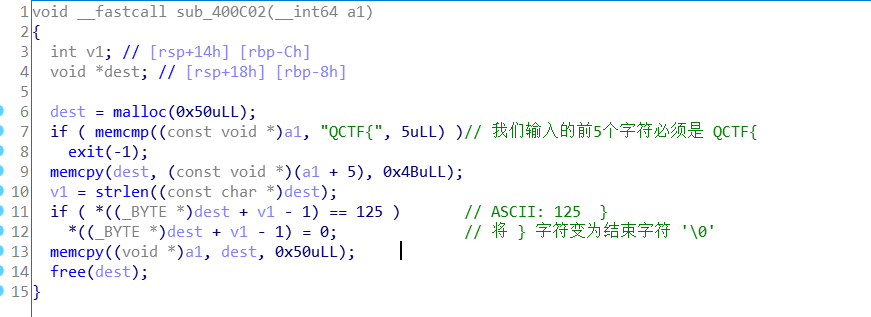
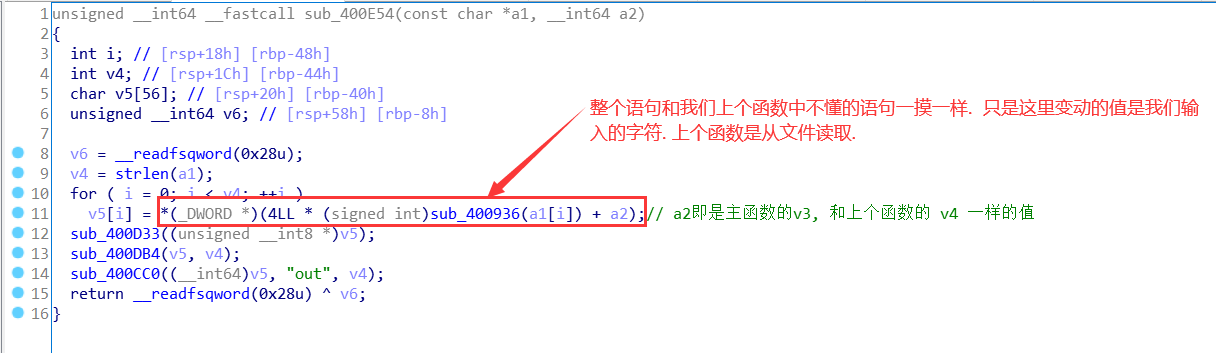
继续看下一个函数sub_400E54 : 看到这里, 就很清晰了, 就是先通过统计that_girl 文件中每个字符出现的次数, 然后按照一定的顺序输入字符, 把每个字符出现的次数按一定顺序给下面的 v5 数组赋值.那所以sub_400936转换字符函数我们是不用管的.
下面是2个加密函数, 我算法太菜, 逆算法想半天😅, 首先sub_400D33((unsigned __int8 *)v5);
然后 sub_400DB4(v5, v4); 解释起来有点抽象……注意是一个字节, 所以多出的位要舍弃
举个例子:
最后一个函数: sub_400CC0((__int64)v5, “out”, v4); 将加密后的值写入 out文件.
0x2逆向解密 exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #include <stdio.h> int main (void ) union { unsigned char ida[152 ]; int change[38 ]; }A = { 22 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 6 , 0 , 0 , 0 , 2 , 0 , 0 , 0 , 30 , 0 , 0 , 0 , 24 , 0 , 0 , 0 , 9 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 21 , 0 , 0 , 0 , 7 , 0 , 0 , 0 , 18 , 0 , 0 , 0 , 10 , 0 , 0 , 0 , 8 , 0 , 0 , 0 , 12 , 0 , 0 , 0 , 17 , 0 , 0 , 0 , 23 , 0 , 0 , 0 , 13 , 0 , 0 , 0 , 4 , 0 , 0 , 0 , 3 , 0 , 0 , 0 , 14 , 0 , 0 , 0 , 19 , 0 , 0 , 0 , 11 , 0 , 0 , 0 , 20 , 0 , 0 , 0 , 16 , 0 , 0 , 0 , 15 , 0 , 0 , 0 , 5 , 0 , 0 , 0 , 25 , 0 , 0 , 0 , 36 , 0 , 0 , 0 , 27 , 0 , 0 , 0 , 28 , 0 , 0 , 0 , 29 , 0 , 0 , 0 , 37 , 0 , 0 , 0 , 31 , 0 , 0 , 0 , 32 , 0 , 0 , 0 , 33 , 0 , 0 , 0 , 26 , 0 , 0 , 0 , 34 , 0 , 0 , 0 , 35 , 0 , 0 , 0 }; int i = 0 , j = 0 , a[100 ] = {0 }, temp = 0 , lenth = 0 ; unsigned char b[100 ] = {0 }, c[2000 ] = {0 }; int count[127 ] = {0 }, change_[38 ] = {0 }; char flag[100 ] = {0 }; FILE *fp = NULL ; fp = fopen("out" , "rb" ); lenth = fread(b, 1 , 100 , fp); fclose(fp); temp = b[lenth-1 ]&7 ; for (i = 0 ; i < lenth; i++) { a[i] = (b[i] >> 3 ) | (temp << 5 ); temp = b[i]&7 ; } fp = fopen("that_girl" , "rb" ); fread(c, 1 , 1742 , fp); fclose(fp); for (i = 0 ; i < sizeof (c); i++) { if (c[i] >= 65 && c[i] <= 90 ) c[i] += 32 ; count[c[i]]++; } i = 0 , j = 0 ; while (A.change[i]) { change_[j++] = A.change[i]; i = A.change[i]; } j -= 1 ; temp = a[0 ], a[0 ] = a[change_[j]]; for (i = 0 ; i < lenth-2 ; i++) { a[change_[j]] = a[change_[--j]]; } a[change_[j]] = temp; for (i = 0 ; i < lenth; i++) { for (j = 0 ; j < 127 ; j++) { if (a[i] == count[j]) { flag[i] = j; break ; } } } printf ("QCTF{%s}" , flag); return 0 ; }
总结: (1)算法好的话, 这道题就轻松很多。(2)注意64位程序的传递参数的方式。
easyre-153 题其实很简单, 能猜到flag怎么算出来, 但对程序的执行想不明白,花了些时间。
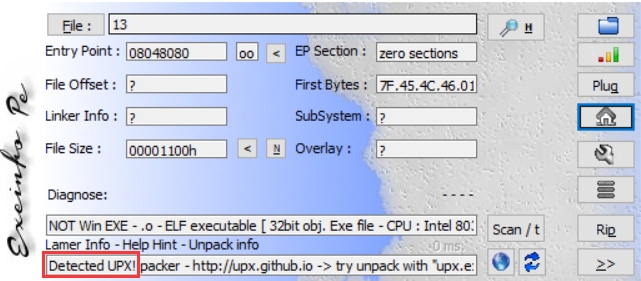
32位elf文件加了upx壳, 没有修改过的, 直接upx -d脱壳成功.
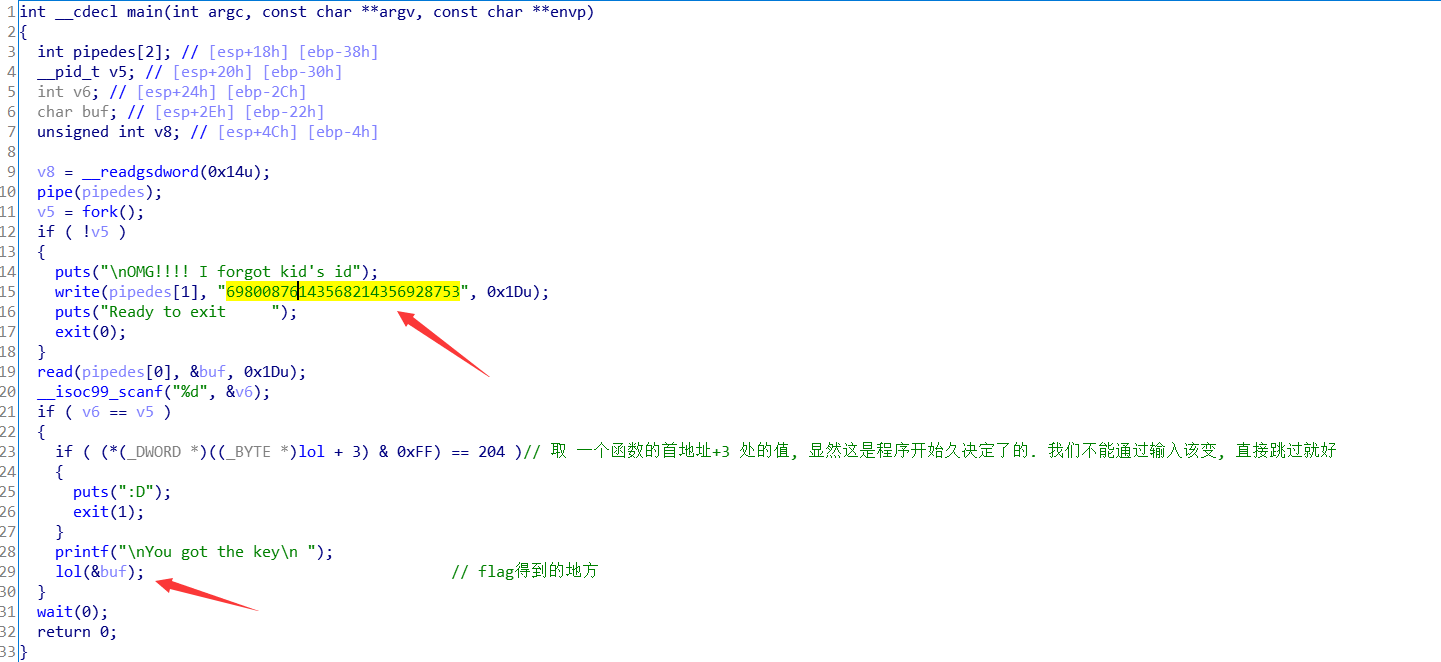
ida打开, 找到主函数. 一开始就认为直接动跳控制函数的走向, 到最后一个 lol 函数得到flag. 但是动态总是在read函数卡住, 走不了, 但这里我们并不能直接跳,因为这个函数是向buf 写内容, 我们最后的flag是要使用buf的内容. 然后又转 GDB 调试, 同然的结果. 纳闷这题了, 它到底是要做什么. 其实猜也是把上面 write的那部分数据作为 buf 的内容, 然后在lol函数得到 flag. 但问题是 程序到底在搞什么…..
真的做到自闭, 后来才发现我忽略上面的 pipe()函数与fork()函数. 第一次见到, 百度了下, 明白了…
首先是管道: 1.其本质是一个伪文件(实为内核缓冲区)
2.由两个文件描述符引用,一个表示读端,一个表示写端。
3.规定数据从管道的写端流入管道,从读端流出
pipe()函数用于创建管道: 1.int pipe(int pipefd[2]); 成功:0;失败:-1,设置errno
2.函数调用成功返回r/w两个文件描述符。无需open,但需手动close
3.规定:fd[0] → r; fd[1] → w,就像0对应标准输入,1对应标准输出一样。
4.向管道文件读写数据其实是在读写内核缓冲区
这里就是通过pipedes[1]写进内容, 从pipedes[0]写出.
然后fork()函数. 1.fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,
也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程 也可以做不同的事
2.一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空 间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程值 不同。相当于克隆了一个自己
3.调用fork函数一次, 返回2次值, 若返回0则是子进程, 若是一个数则是父进程的进程号.
所以这里就是先创建一个子进程,返回值v5 == 0, 进入子进程完成写入数据后结束进程, fork()返回新的值父进程进程号,然后执行后面的操作.
这里动态调试这种创建进程的程序是不通畅的. 那就通过修改程序 EIP, 按照本来要执行的顺序执行一遍得到flag.(注意这样可能会有一个问题: 栈不平衡, 因为函数没有正常返回, 那会影响一些函数, 比如scanf()函数执行到了, 不会让我们输入, 而是直接跳过, 这就是堆栈有值它就直接读取了)
总结:(1)对于盲区的知识, 搞起来还是麻烦,积累吧。 (2)熟悉了修改 EIP。
76号公路 题目看似很难的样子, 但自己确实被题目的信息误导了.
下载后, 2个文本一个32位无壳elf文件, 并且题目信息就给了 我们认为有份确切的文档记录了每个区域的功能,请协助找出 这个提示, 所以自己做题时始终想到怎么和文本联系起来, 找线索. 但其实不然
载入ida后, 搜索了下字符串, 找到了主函数, 但是不能转化为伪代码, 因为之前了解过点花指令,其中 E0 总是干扰代码的. 改为 90 nop掉就可以了.
这里同样. 改完后, 开始读汇编代码, 逻辑很简单, 就是提示, 让我们输入字符, 进去一个函数判断.
进去判断函数, 可以查看伪代码的. 分析一下就知道是跟着一条线按照顺序检索我们输入的字符串. 但是怎么找顺序呢, 因为文本文件还没用, 我就始终认为在文本文件找, 找了半天…….无果
最后回到程序发现, 可以找到入口点, 顺藤摸瓜的就可以找到了啊. 可以知道从索引 v2 从0开始, 直接从这里出发就好了. 直到正确退出循环.
最后得到flag: flag{09vdf7wefijbk} .
总结: (1)不要让题目把自己的思路带偏了, 思维要发散一些.
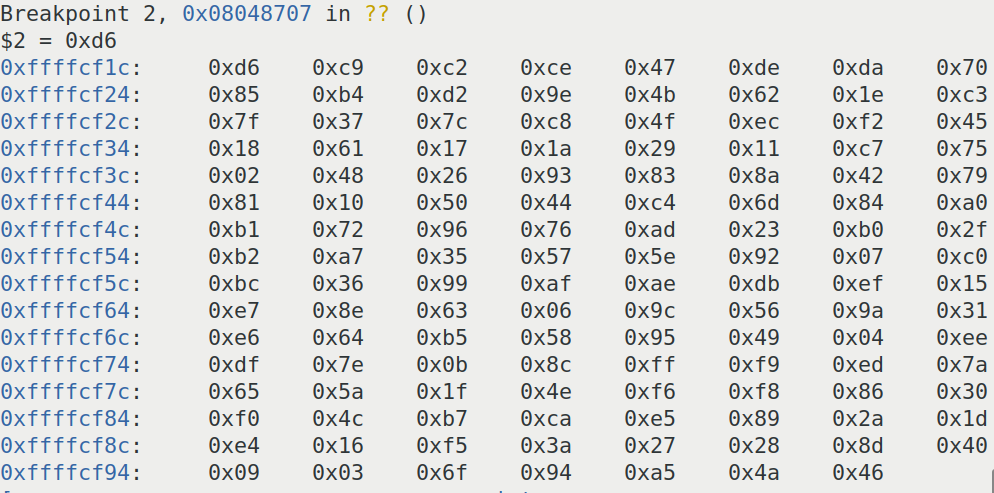
reverse-box 题目下载下来,弄半天始终觉得有问题。百度发现题目少给了输出字符串。
开始再次看题,被自己坑惨了。。。因为生成数据表的函数中自己只看到了生成的随机数赋值了给了数据表的第一次元素,那整个题就有点奇怪了。看了又看,才发先最后用到了随机数生成数据的,只是屏幕容不下了。。。
另外就是先将每次生成索引值 v7 用C语言写出来后打印看看, 但大多数是负数,很大的数。这显然不对的,因为我们运行程序时输入的参数都是可打印字符 (ASCII: 32-127),伪代码不靠谱,果断去看看了汇编。
另外就是 伪代码中的 __ROR__了,看了汇编知道了 ror 指令,将数据想右位移动指定的位数。以为只是简单的 >> ,就这样写了整个题的爆破代码。但是始终不对,花了很时间,不甘心,就ida中动调,C语言中调试,每个步骤对比结果,才找到是 ror 这里错了。。。 原来 ror 是右移动位后会把多余的位移动到最左边,即一个圆圈转,这是循环移位。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include <stdio.h> #include <stdlib.h> #include <string.h> void generate (int a, int *result) int v7 = 1 , v2 = 0 , v3 = 0 , temp = 0 ; int v4 = 0 , v5 = 0 , v8 = 1 , v9 = 0 ; result[0 ] = a; do { v2 = v7 ^ 2 * v7; if ((v7 & 0x80 ) == 0 ) v3 = 0 ; else v3 = 27 ; v7 = v2 ^ v3; v7 = v7 & 0xFF ; v4 = (4 * (2 * v8 ^ v8) ^ 2 * v8 ^ v8)&0xff ; v9 = ((16 * v4 ^ v4)&0xff ); if ( v9 >= 0 && v9 <= 127 ) v5 = 0 ; else v5 = 9 ; v8 = (v9 ^ v5); if (v7 < 127 ) result[v7] = (((v8 >> 4 ) | ((v8 & 0xF ) << 4 )) ^ ((v8 >> 5 ) | ((v8&0x1F ) << 3 )) ^ ((v8 >> 6 ) | ((v8&0x3F )<<2 ) ) ^ ((v8 >> 7 ) | ((v8&0xFF )<<1 ) ) ^ (v8 ^ a))&0xff ; }while (v7 != 1 ); } int main (void ) int *result = (int *)malloc (sizeof (int )*127 ); int i = 0 , value = 0 , j = 0 ; char a[] = "95eeaf95ef94234999582f722f492f72b19a7aaf72e6e776b57aee722fe77ab5ad9aaeb156729676ae7a236d99b1df4a" ; for (i = 1 ; i < 256 ; i++) { generate(i, result); if (result[84 ] == 0x95 ) break ; } for (i = 0 ; i < strlen (a); i += 2 ) { if (a[i] >= 48 && a[i] <= 57 ) a[i] -= 48 ; else a[i] -= 87 ; if (a[i+1 ] >= 48 && a[i+1 ] <= 57 ) a[i+1 ] -= 48 ; else a[i+1 ] -= 87 ; value = a[i+1 ] | a[i]*16 ; for (j = 32 ; j < 127 ; j++) { if (result[j] == value) { printf ("%c" , j); break ; } } } }
做完去看了看网上的 writeup, 发现都是用gdb写脚本搞的,然后去学习了下。
使用 gdb的 define 命令可以定义一系列的gdb指令。首先找到要下断点地址,这个在ida中很容易。
这里有2中方法,执行gdb脚本,一:直接输入define命令,输入指令,最后执行。二:单独写成一个脚本文件使用 source 来执行。
这里直接写的脚本文件使用 source执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 set $i = 0 set $total = 256 while ($i < $total) b *0x80485b4 b *0x8048707 run T set $i = $i+1 set *(char*)($ebp-0xc ) = $i continue if ($eax == 0x95 ) print $i x/127 xb $esp+0x1c set $i = 256 stop end
因为可打印字符的ASCII:32-127,所以我们打印出前128个数据即可。最后解密。python确实方便,各种方法直接调用即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 list = [0xd6 ,0xc9 ,0xc2 ,0xce ,0x47 ,0xde ,0xda ,0x70 ,0x85 ,0xb4 ,0xd2 ,0x9e ,0x4b ,0x62 ,0x1e ,0xc3 ,0x7f ,0x37 ,0x7c ,0xc8 ,0x4f ,0xec ,0xf2 ,0x45 ,0x18 ,0x61 ,0x17 ,0x1a ,0x29 ,0x11 ,0xc7 ,0x75 ,0x02 ,0x48 ,0x26 ,0x93 ,0x83 ,0x8a ,0x42 ,0x79 ,0x81 ,0x10 ,0x50 ,0x44 ,0xc4 ,0x6d ,0x84 ,0xa0 ,0xb1 ,0x72 ,0x96 ,0x76 ,0xad ,0x23 ,0xb0 ,0x2f ,0xb2 ,0xa7 ,0x35 ,0x57 ,0x5e ,0x92 ,0x07 ,0xc0 ,0xbc ,0x36 ,0x99 ,0xaf ,0xae ,0xdb ,0xef ,0x15 ,0xe7 ,0x8e ,0x63 ,0x06 ,0x9c ,0x56 ,0x9a ,0x31 ,0xe6 ,0x64 ,0xb5 ,0x58 ,0x95 ,0x49 ,0x04 ,0xee ,0xdf ,0x7e ,0x0b ,0x8c ,0xff ,0xf9 ,0xed ,0x7a ,0x65 ,0x5a ,0x1f ,0x4e ,0xf6 ,0xf8 ,0x86 ,0x30 ,0xf0 ,0x4c ,0xb7 ,0xca ,0xe5 ,0x89 ,0x2a ,0x1d ,0xe4 ,0x16 ,0xf5 ,0x3a ,0x27 ,0x28 ,0x8d ,0x40 ,0x09 ,0x03 ,0x6f ,0x94 ,0xa5 ,0x4a ,0x46 ] flag = "" s = "95eeaf95ef94234999582f722f492f72b19a7aaf72e6e776b57aee722fe77ab5ad9aaeb156729676ae7a236d99b1df4a" ; for i in range(0 , len(s), 2 ): s1 = int(s[i:i+2 ], 16 ) flag += chr(list.index(s1)) print (flag)
总结:这道题收获还是很大。1:对ida中汇编语言的解读更熟悉了些,注意各种 al 取最低字节数据。 2:ror指令的了解,及对他的C语言用法:如 ror a,3 那C语言为:((a>>3)| ((a&7) << 5))。 3:使用gdb写脚本。
gdb脚本中的 查看内存内容的方法:x/<n/f/u> n、f、u是可选的参数。
n:显示的内存单元的个数,f:表示显示的格式,其中:s:字符串显示,x:按十六进制格式显示,d:按十进制格式显示变量
u:按十六进制格式显示无符号整型,t:按二进制格式显示, o:按八进制格式显示,c:按字符格式显示变量。
最后的u表示每个单元的大小,其中:b表示单字节,h表示双字节,w表示四字 节,g表示八字节。
那上面脚本写的 x/127xb 表示将 127个的单字节单元的数据按16进制格式显示出来。
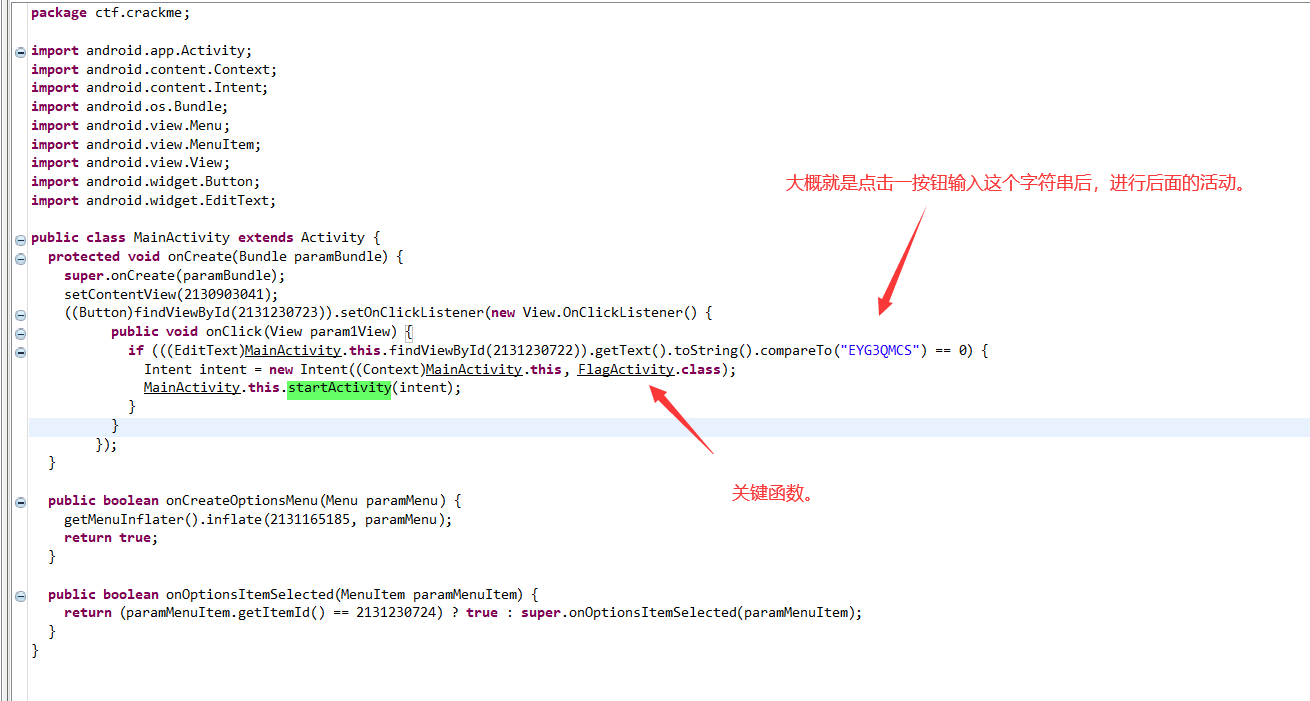
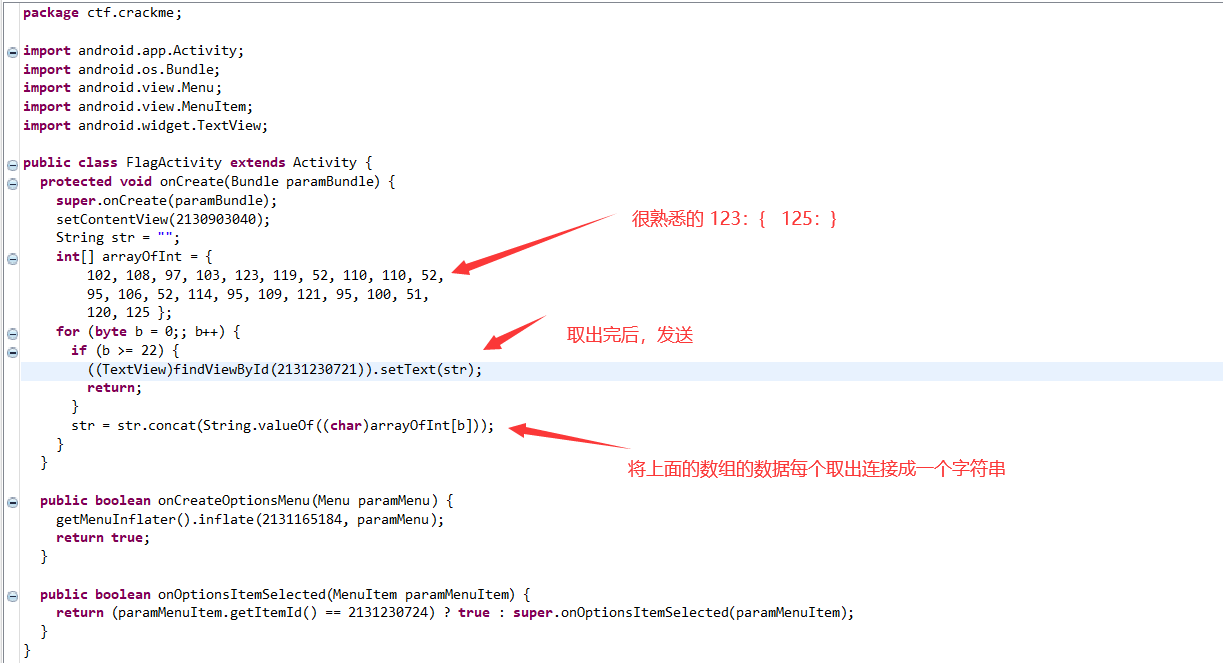
很简单的一道安卓逆向,为什么分数那么高。。。
下载解压后得到一堆文件,对安卓逆向没深入了解过,直接找到 .dex文件,使用强大的 ApkToolkit 工具转 .dex文件为 .jar文件。
接着就是使用 jd-gui 打开,看反编译的java代码。
看 FlagActivity.class,就是直接取出flag。
打印出来就好了。flag: flag{w4nn4_j4r_my_d3x}
总结:安卓逆向也是遇到一道,然后做来试试看,但也只能做很简单的,暂时熟悉工具吧。
re5-packed-movement 对于全是mov指令,这道题看了writeup做的,学习了ida中脚本的使用。
32位elf文件加了upx壳,直接使用 upx -d。
打开全是mov指令,心想这又是什么骚操作,一波操作后还是不会。后面发现都是用ida脚本实现,那其实也可以用gdb脚本。
学习一番ida脚本及idc的语法,开始做题。先找到代码段地址,因为考虑flag是通过立即数mov指令赋值的。
写脚本搜索四个字节的所有可打印字符。
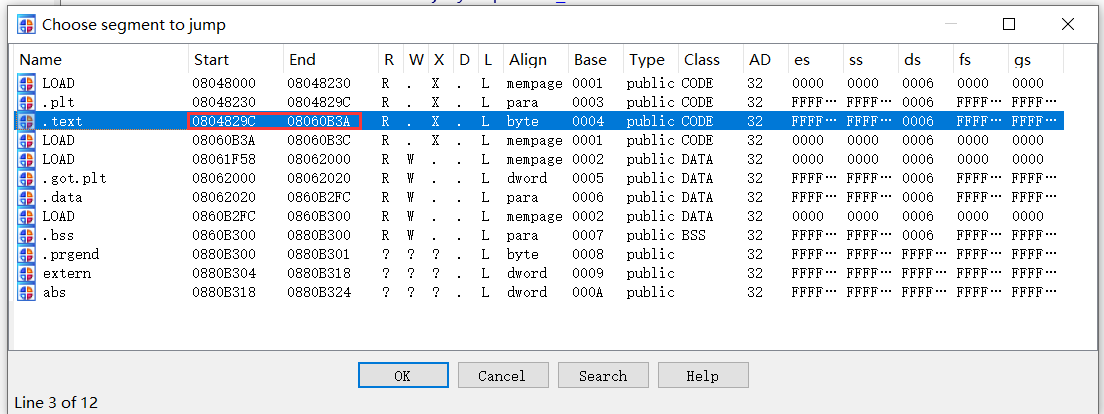
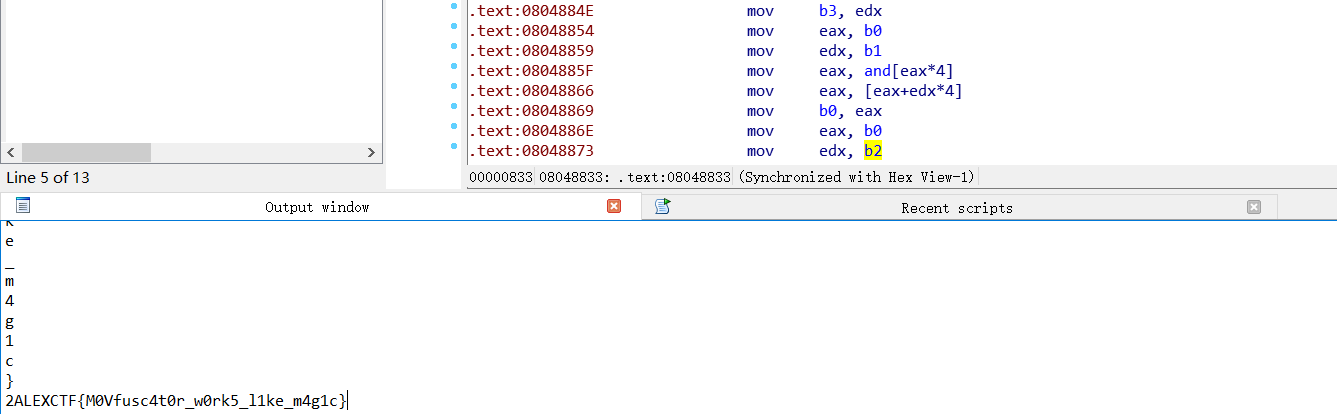
1 2 3 4 5 6 7 8 9 10 11 12 start=0x0804829C end=0x08060B3A flag = "" while start<end: if (Byte(start) <= ord('9' ) and Byte(start)>=ord('0' )) or (Byte(start)<=ord('z' ) and Byte(start)>=ord('a' )) or (Byte(start)<=ord('Z' ) and Byte(start)>=ord('A' )) or (Byte(start) == ord('}' )) or (Byte(start) == ord('{' )) or (Byte(start) == ord('_' )) or (Byte(start) == ord('@' )) or (Byte(start) == ord('!' )) or (Byte(start) == ord('#' )) or (Byte(start) == ord('&' )) or (Byte(start) == ord('*' )): if Byte(start) and (Byte(start+1 )==0 ) and (Byte(start+2 )==0 ) and (Byte(start+3 )==0 ): print(chr(Byte(start))) flag += chr(Byte(start)) start += 1 print(flag)
执行。
总结:对ida脚本进行了学习,开始对ida执行脚本有所了解。
梅津美治郎 很简单一个题目,关键就是一点,使用了函数AddVectoredExceptionHandler()。
1 2 3 4 PVOID AddVectoredExceptionHandler ( ULONG First, PVECTORED_EXCEPTION_HANDLER Handler )
查看官方文档可知,此函数作用:注册一个异常处理程序 。即当我们的程序中出现异常后会执行的函数。
程序在此处触发异常:
easy_go go语言写的程序,谷歌了下去除符号表golang编译的程序的处理方法。
可以使用一个脚本IDAGolangHelper 来还原符号表,那将极大方便我们分析程序。
但是ida7.0因为版本低的原因,使用这个脚本会有问题。然后找到解决办法:https://blog.csdn.net/qq_21063873/article/details/104335240
成功还原符号表后,找到main_main函数,主逻辑还是能清楚,但细节的地方真的难看。。
发现base64相关的函数:
然后动调想看看自己输入的字符串存放在哪里也找不到。。。但是动调出了2个字符串,其中一个正好是64位,考虑是变异的base64加密,另一个字符串是输入flag的密文。
写脚本尝试解:还真的得到flag。。
1 2 3 4 5 6 7 8 9 10 11 12 13 import base64base1 = '6789_-abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ012345' t = 'tGRBtXMZgD6ZhalBtCUTgWgZfnkTgqoNsnAVsmUYsGtCt9pEtDEYsql3' base = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' ans = '' for i in t: ans += base[base1.index(i)] print(ans) print(base64.b64decode(ans))