关于memset赋初值
一个优先级问题
在刚学指针时写了
while(c = *(p++) != '\0'),但是一直得不到自己想要的结果。原因在于这里
!=的优先级大于=, 所以先执行了*(p++) != '\0',而这个的结果是以一个boolean值,只有2种结果 0 或 1。故c = 1 或 0 了。
缓冲区
一:什么是缓冲区?
- 缓冲区又称为缓存,它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。
- 缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
二:为什么要引入缓冲区?
- 比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
- 又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。
- 缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
三:缓冲区的类型。
区分为三种类型:全缓冲、行缓冲和不带缓冲。
全缓冲
在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。
行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是键盘输入数据。
不带缓冲
也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
四:刷新缓冲区
- 在我们C语言文件操作中使用
fclose()函数就有那种作用。
关于联合位域,小端
在一般的我们平常使用的计算机, 数据存储方式都是小端, 但是C语言编译器都会经过处理, 所以总是按一个类型, 倒序显示。
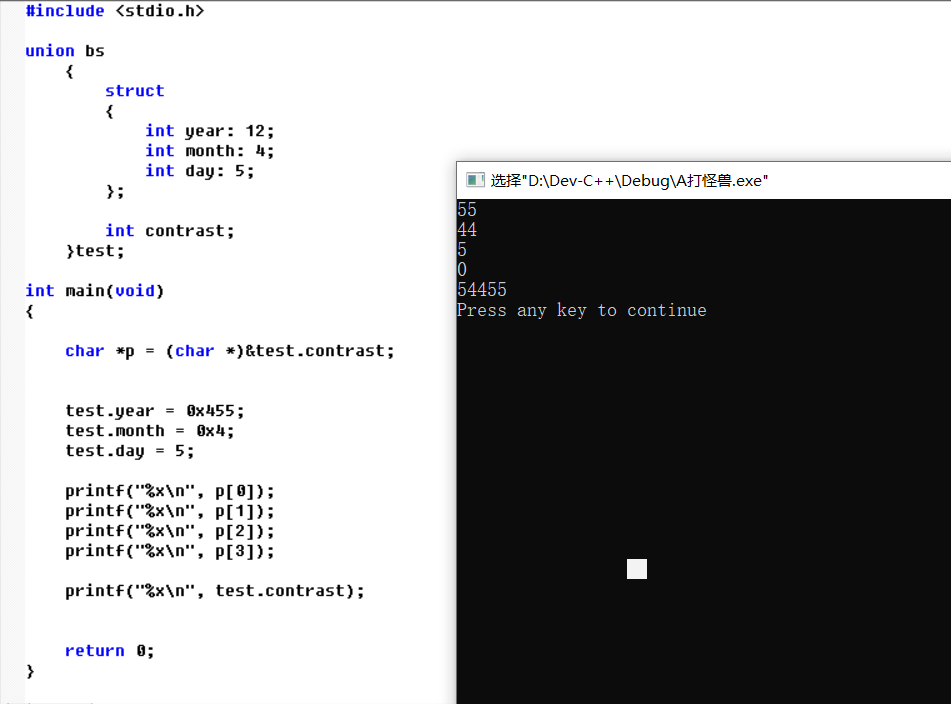
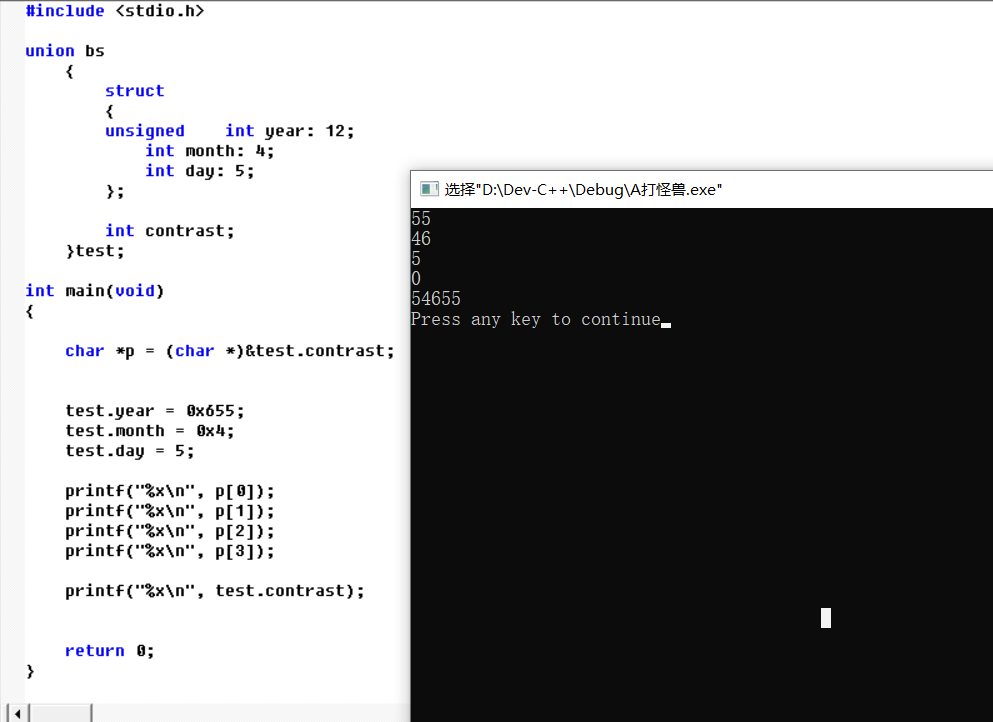
从以上两个图片可以看出, 当结构体中位域定义时. 是从左往右一个字节一个字节进行定义, 在一个字节中也是从低位bit0 开始算起的(注意不是从高位开始对应)。
如上图中 test.year = 0x655, year有12位. 但是在多出的4位中, 06在该字节的低位, test.month = 0x4在该字节的高位。
当相邻成员的类型相同时,如果它们的位宽之和小于类型的 sizeof 大小,那么后面的成员紧邻前一个成员存储,直到不能容纳为止;如果它们的位宽之和大于类型的 sizeof 大小,那么后面的成员将从新的存储单元开始,其偏移量为类型大小的整数倍。 若不是同类型, 则不会, 注意(int 与 short int)也是不同类型.。
二维数组形参问题
- 当二维数组作为参数传递给函数时,函数的形参不能简单地写双重指针。
- 因为编译器实际寻址如下:对于数组 int p[m][n];如果要取p[i][j]的值,编译器是这样寻址的:p + i*n + j; 如果我们省略了第二维或者更高维的大小,编译器将不知道如何正确的寻址。因此如果我们在编写程序的时候需要用到各个维数都不固定的二维数组作为参数,虽然这个时候编译器还是不能识别。
- 我们可以把二维数组当做普通的指针,将它的大小用两个参数指明,然后我们为二维数组手工寻址,这样就可以将二维数组作为函数的参数传递了,我们可以把维数固定的参数变为维数随即的参数。
需要用getchar()吃掉回车的情况
- 接受字符或字符串的前面有
scanf()语句。 - 连续使用2个
getchar()接受字符时,中间要使用一个getchar()吃掉回车。 - scanf();后如果是是用gets()输入字符串,那必须先吃掉回车;如果是用scanf(“%s”, );输入字符串可以不吃掉回车。
注意:gets()后面是不需要吃掉回车的,因为它把回车转化为了字符串最后的 ‘\0’ 。
文件操作
对于文件写入方式主要还是与使用的函数有关,与打开方式关系不大。
文本形式写入
1
2
3
4
5
6
7
8
9
10
11
12
int main(void)
{
int a = 100;
FILE *fp = NULL;
fp = fopen("lines", "w");
//fwrite(&a, 1, 4, fp);
fprintf(fp, "%d", a);
return 0;
}
二进制形式写入
1
2
3
4
5
6
7
8
9
10
11
12
int main(void)
{
int a = 100;
FILE *fp = NULL;
fp = fopen("lines", "wb");
fwrite(&a, 1, 4, fp);
//fprintf(fp, "%d", a);
return 0;
}
从以上可以很清楚他们的区别。
关于一个格式说明符
- 之前由于受到 %02d 类似的表达,不足2位用2填充,超过2位就原样。
- 然后了%10s,自己就默认了还是那个意思,其实这里是截断的意思,超过10位的留在缓冲区。
指针与数组
以前学习指针时的一个疑问。

因为我们初始化一个数组时,数组的初始值放在rodata段里面.数组对应开辟的空间上的数值存放在栈上,编译器会去访问rodata段上的初始值然后取来初始化局部变量,因此数组的值才能修改. 而指针指向的是rodata段,是不能被修改的
补码的总结
对于一个有符号的char型数据。
有 -1-128 = 127, 127+1 = -128;, 再结合之前看到的补码和时钟原理很像, 自己总结了下, 可以把这个计算想成是一个圆圈, 以一个字节8位来看, 我们知道范围是 -128 - 127
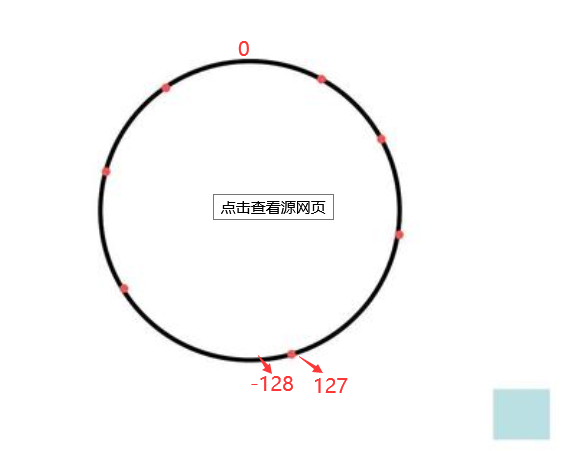
知道一个周期的大小是 256. 那么有 -1+1= 0 也可以写成 -1 - 255 = 0, 相当于 -1 逆时针转了 一圈少1的距离, 那么就是0的位置, 因为如果转了一圈的话, 回到原位置,. 顺时针加法也是一样的原理, 0 + 256 = 0。
qsort的比较函数的注意
qsort的比较函数的返回值是int,这次题目的数据是浮点数,所以如果当两个浮点数相差小于1的时候,返回的值为变成int型的0,那就不会发生排序了。即我用的return q->price_single - p->price_single;,当他们2个数相差小于1就返回0,导致结果是不排序。这里正确的写法应该是return q->price_single > p->price_single;,以后都写大于小于了。
2020/8/4
今天,从一道题因为比较函数cmp使用不当,导致排序一直出错。进而对C语言的qsort与C++的sort他们的比较函数cmp进行了深究。
首先说说问题,以前一直在比较函数习惯写retrun a-b这种格式,自从出了上面所述的关于浮点数的比较问题,统一换成了使用return a > b的格式,今天问题来了,这样写一直排序不正确。换了C语言版本又是正确的了。。其实这种return a > b的格式是更高级的写法吧,像gcc编译器都是可以的,但devc与vc6都不行。兼容的写法:*return *(int *)a > *(int *)b ? 1:-1;*,原因后面再叙述。
学习中又看见C++中sort函数的cmp函数,初步发现它和qsort的cmp函数是相反的写法。。而对于sort的cmp函数只有一种写法:return a > b;(从大到小排序),return a < b;(从小到大排序),它的实质就是返回值为1表示2个数据不交换,返回值为0表示2个数据交换。这也就说明也sort的cmp不能写return a-b;的格式。
最后来说说关于qsort的cmp实质:返回值为1表示数据需要交换,返回值为-1不需要交换,0表示不确定。所以qsort的cmp的return a > b就出现了不确定性,只能返回1或0,改进写法就是对它的详细化。
上面说的也是很乱,最后总结一下:qsort的cmp使用:return *return *(int *)a > *(int *)b ? 1:-1;*(-1与1的先后决定排序方式),sort的cmp使用:return a > b;(从大到小排序),return a < b;(从小到大排序)
至于等于号写不写,看排序需不需要对相等的数排序交换。
最后:sort是qsort的升级,sort还是方便许多。
关于strcmp函数
ANSI标准规定,返回值为正数,负数,0 。而确切数值是依赖不同的C实现的。
1.当两个字符串不相等时,C标准没有规定返回值会是1 或 -1,只规定了正数和负数。
2.有些会把两个字符的ASCII码之差作为比较结果由函数值返回。但无论如何不能以此条依据作为程序中的流程逻辑。
1 |
|
上面所说的确切数值依赖不同的C实现,刚刚去看了不同C版本的strcmp的源码,果然有的版本确实是返回:1,-1,0。
所以为了能在不同平台上兼容,以后统一写:>0,==0,<0
关于scanf
当使用scanf()不是%c的格式化字符串输入时,它不会接受空格与回车。当输入的是空格与回车,它会一直等待用户输入非空格与回车。
也就是它会跳过空格的意思,空格或回车作为输入结束的标志。
另外注意:这里只有接受空格,如果不是则跳过这个函数,缓冲区里的值不变。
最后:当我们前面因为有输入导致缓冲区里有空格或回车时,后面是使用scanf()非%c输入,我们是不需要先吃掉回车的,因为scanf()会跳过它。
运算符优先级
百度经验一个文章整理的十分清楚,自己造轮子也没必要,转载一下:https://jingyan.baidu.com/article/ae97a646c865ccbbfd461dd3.html
最高级:出现同级别运算符时的结合方向是从左往右(下面级别没写结合顺序时,默认是从左往右)。
( )圆括号
[ ]下标运算符号
->指向结构体成员运算符
.结构体成员运算符

第二级:!、~、++、–、-、(类型)、*、&、sizeof。
这一级都是单目运算符号,这一级的结合方向是从右向左。
比如出现p++,这时和++同级别,先算右边,再左边。
所以p++等价于(p++),而不是(*p)++。

第三级:+、-、*、/、%
这一级都是算术运算符,结合顺序和数学学习中一致的,先乘除取余数,后加减。

第四级:<<、>>
这是左移、右移运算符,位运算时可能需要用到。

第五级:<、<=、>、>=、!=、==
这些运算符也称为关系运算符,其中<、<=、>、>=高于!=、==。

第六级:&、^、|
这三个符号也是位运算符号,其中内优先级,&>^>|。

第七级:&&、||
逻辑与&&优先级大于逻辑或||。

第八级:? :
也称为条件运算符号,是C语言中唯一的一个三目运算符,结合顺序是从右往左。

第九级:=、+=、-+、*=、/=、%=
这些运算符也叫做赋值运算符,除此之外,>>=、<<=、&=、^=、|=这些赋值运算符也在这一级别内,结合顺序是从右往左。

最低级:,
逗号运算符也称为顺序求值运算符,在C语言中,运算级别最低。

小结
总的来说,初级运算符( )、[ ]、->、. 高于 单目运算符 高于 算数运算符(先乘除后加减) 高于 关系运算符 高于 逻辑运算符(不包括!) 高于 条件运算符 高于 赋值运算符 高于 逗号运算符。
位运算符的优先级比较分散。
除了赋值运算符、条件运算符、单目运算符三类的平级运算符之间的结合顺序是从右至左,其他都是从左至右。